


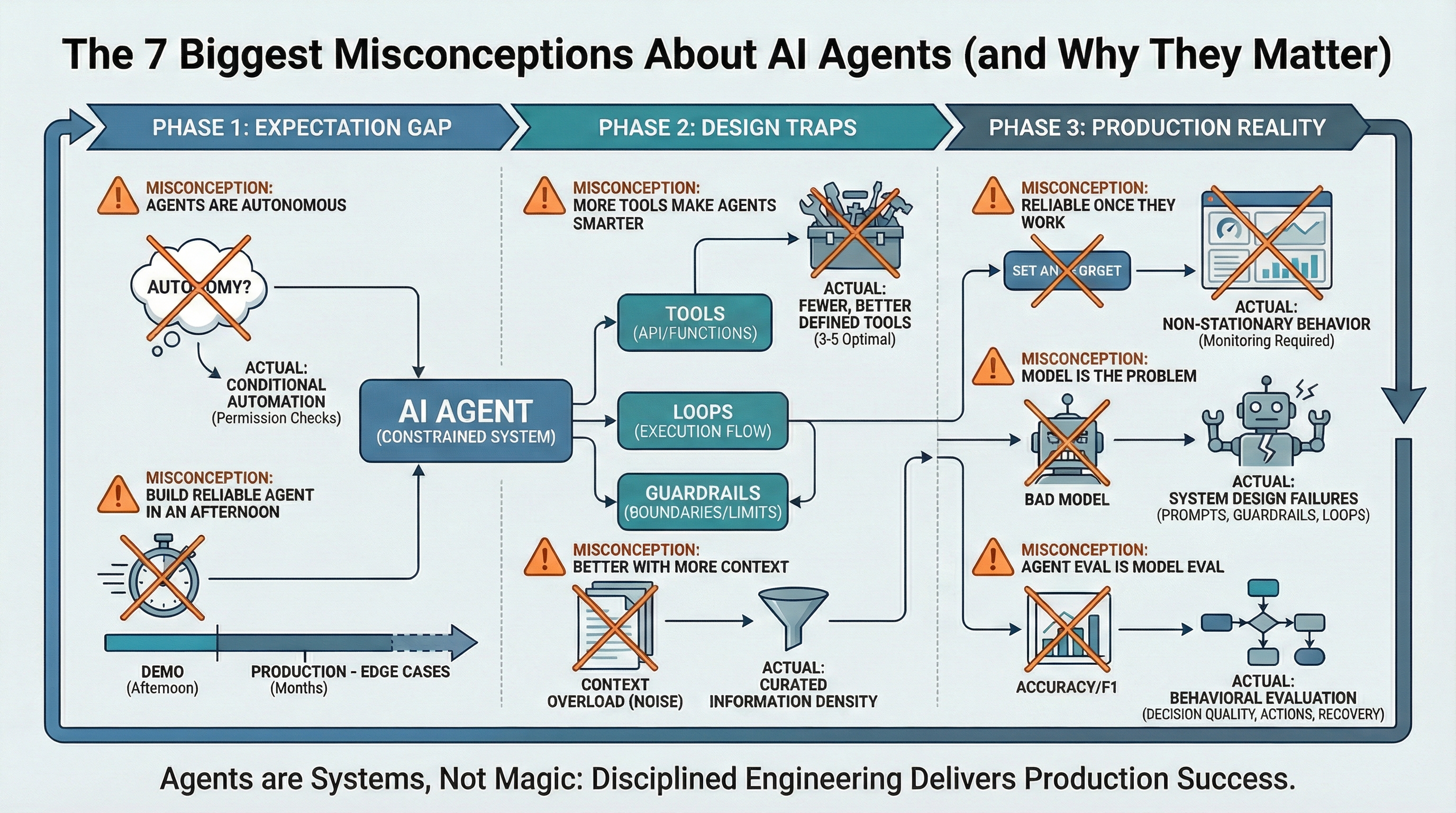
The 7 Biggest Misconceptions About AI Agents (and Why They Matter) (click to enlarge)
Image by Author
AI agents are revolutionizing industries, from sophisticated customer support automation to intelligent code generation. These systems promise autonomous operation, making critical decisions and executing tasks without constant human oversight.
However, widespread misunderstandings about AI agent capabilities frequently derail projects. These misconceptions are not trivial; they directly cause costly production failures, budget overruns, and erosion of stakeholder trust. The chasm between simulated demo performance and real-world application is the graveyard of many AI agent initiatives.
This analysis dissects the seven most impactful misconceptions surrounding AI agents, categorized by their relevance to the agent lifecycle: establishing initial expectations, formulating robust design decisions, and managing ongoing production operations.
Phase 1: Mastering Initial Expectations
Misconception #1: "AI Agents Possess True Autonomy"
Reality: AI agents are sophisticated conditional automation tools, not truly autonomous entities. They do not independently formulate objectives. Their actions are meticulously constrained by predefined parameters: specific tool utilization, precisely engineered prompts, and explicit termination protocols. Apparent autonomy arises from a controlled execution loop featuring rigorous permission validation. While an agent can perform sequential actions, it is strictly confined to paths previously authorized by its operators.
Strategic Implication: Overestimating agent autonomy invites deployment risks. Development teams may neglect essential guardrails, operating under the flawed assumption that the agent inherently understands and avoids hazardous actions. This is a dangerous fallacy; genuine autonomy necessitates intent, whereas agents operate based on established execution patterns.
Misconception #2: "Production-Ready Agents Can Be Developed Swiftly"
Reality: While an initial agent prototype can be assembled rapidly, achieving robust production-level reliability demands months of meticulous engineering. The critical differentiator lies in comprehensive edge-case management. Demonstrations typically showcase controlled environments with idealized, happy-path scenarios. Production agents, conversely, must reliably handle malformed inputs, API communication failures, unpredictable tool responses, and dynamic context shifts during execution. Each potential edge case requires explicit, robust handling mechanisms, including sophisticated retry logic, alternative fallback pathways, and graceful degradation strategies.
Strategic Implication: This expectancy gap precipitates significant project timeline and budget overruns. Teams often present a functional agent prototype, secure stakeholder approval, only to subsequently dedicate extensive periods to rectifying production issues that were unforeseen. The true engineering challenge is not enabling a single successful execution, but ensuring persistent operational integrity.
Phase 2: Navigating Design Pitfalls
Misconception #3: "Expanding Toolsets Enhances Agent Intelligence"
Reality: Paradoxically, introducing an excessive number of tools degrades agent performance. Each additional tool diminishes the statistical probability that the agent will select the optimal tool for a given task, thereby amplifying confusion. Tool overload leads to agents initiating incorrect tool calls, supplying improperly formatted parameters, or bypassing tool execution altogether due to an overwhelmingly complex decision space. Optimal production agents typically function most effectively with a curated selection of 3-5 specialized tools, rather than an unwieldy array of twenty.
Strategic Implication: Agent failures are predominantly rooted in suboptimal tool selection, not inherent reasoning deficiencies. When an agent produces erroneous or nonsensical output, it is typically because it has chosen an inappropriate tool or executed actions in an incorrect sequence. The solution lies not in enhancing the underlying model, but in refining and reducing the toolset to fewer, more precisely defined functionalities.
Misconception #4: "Augmented Context Universally Improves Agent Performance"
Reality: Excessive contextual information actively degrades agent performance. Injecting extensive documentation, prolonged conversation histories, and broad background data into prompts does not augment the agent's intelligence. Instead, it introduces noise, obscuring critical signals and diminishing retrieval accuracy. The agent may then retrieve irrelevant information or overlook essential details due to the sheer volume of content it must process. Furthermore, exceeding token limits significantly inflates operational costs and introduces unacceptable latency.
Strategic Implication: Information density demonstrably outperforms sheer information volume. A carefully curated context of 2,000 tokens can yield superior results compared to an unoptimized 20,000-token data dump. If your agent is exhibiting poor decision-making, rigorously assess whether it is struggling with contextual overload before attributing the issue to a fundamental reasoning deficit.
Phase 3: Confronting Production Realities
Misconception #5: "Achieved Functionality Equates to Enduring Reliability"
Reality: Agent behavior is inherently non-stationary. Identical inputs do not guarantee consistent outputs over time. External factors such as API modifications, variable tool availability, and even minor prompt adjustments can induce significant behavioral drift. Subsequent model updates can subtly alter how an agent interprets instructions, leading to a degradation in performance from previously reliable states. An agent functioning flawlessly one week may exhibit compromised performance the next.
Strategic Implication: Reliability issues in AI agents are rarely apparent during controlled demonstrations. They manifest in production environments, particularly under load and over extended operational periods. Continuous deployment of agents is not a viable strategy; robust monitoring, comprehensive logging, and diligent regression testing of critical behaviors are imperative, extending beyond mere output validation.
Misconception #6: "Model Imperfection is the Root Cause of Agent Failures"
Reality: Agent failures are overwhelmingly attributable to systemic design flaws, not inherent model limitations. Common culprits include inadequately specified prompts that omit critical edge-case handling, insufficient guardrails that permit agent operational spirals, weak termination criteria leading to infinite loops, and poorly defined tool interfaces yielding ambiguous outputs. Attributing failure solely to the model is a facile, yet inaccurate, approach. Rectifying the orchestration layer presents a far more complex, yet essential, engineering task.
Strategic Implication: When development teams default to the conclusion that "the model is insufficient," valuable resources are diverted towards awaiting future model releases rather than addressing the actual points of failure within the system's architecture. Agent-related problems are frequently solvable through refined prompts, clearly defined tool contracts, and more stringent execution boundaries.
Misconception #7: "Agent Evaluation Mirrors Standard Model Evaluation"
Reality: AI agents demand evaluation based on observable behavior, not solely on textual output quality. Traditional machine learning metrics, such as accuracy or F1 scores, are insufficient for capturing critical agent performance aspects. Key questions include: Did the agent select the appropriate action? Did it terminate execution as intended? Did it gracefully recover from encountered errors? Evaluating decision quality, rather than text quality alone, is paramount. This necessitates systematic tracking of tool-selection accuracy, loop termination rates, and the efficacy of failure recovery mechanisms.
Strategic Implication: A sophisticated language model can generate high-quality text while simultaneously exhibiting detrimental agent behavior. Without an evaluation framework that scrutinizes actions, the most significant failure modes will remain undetected. This includes agents incorrectly invoking APIs, expending valuable tokens on irrelevant processing loops, or failing without generating discernible error signals.
AI Agents: Engineered Systems, Not Inherent Intelligence
The most successful AI agent implementations categorize agents as sophisticated engineered systems, rather than entities possessing innate intelligence. Their success stems from the imposition of rigorous constraints, rather than an implicit reliance on the model's capacity for independent problem-solving. True autonomy is a deliberate design outcome. Sustained reliability is cultivated through diligent monitoring practices. Failure is an emergent property of the system architecture, not a fundamental flaw of the underlying model.
For practitioners developing AI agents, an approach grounded in healthy skepticism is essential. Assume potential failures in unforeseen scenarios. Prioritize containment mechanisms and robust design over sheer capability. While the prevailing hype suggests autonomous, sentient intelligence, the practical reality demands disciplined, rigorous engineering practices.