


AI agents can reason, plan, and act. They are used in many AI applications. Examples include coding help and health coaches. The industry is moving to longer tasks. Instead of just answering questions, agents work in steps. We need new ways to check how well agents work. Old ways only check accuracy. Agents are more complex. One error can cause more problems later. We need to know how to build the best agent systems.
People often think more agents are always better. They believe adding special agents will always help. Some studies show that more AI models improve performance. Other research found that agents working together can be smarter than one agent alone.
Our new paper, \u201cTowards a Science of Scaling Agent Systems,\u201d looks at this idea. We tested 180 different agent setups. We found rules for how agent systems get better. The idea that more agents are always better is not always true. Sometimes, too many agents can make things worse. It depends on the task.
How we tested agents
We needed to know what makes a task need an "agent." Old tests only check a model's knowledge. They don't show how well it works in real use. We say that agent tasks need three things:
- Tasks need many steps over time. The agent works with its world.
- The agent needs to find information. It doesn't know everything at first.
- The agent must change its plan. It learns from what happens in the world.
We tested five main setups. One used a single agent (SAS). Four used many agents. We tested them on different tasks. These tasks included finance help, web browsing, planning, and using tools. Here are the agent setups:
- Single-Agent (SAS): One agent does everything. It remembers things and acts step by step.
- Independent: Many agents work on their own. They don't talk to each other. They combine results at the end.
- Centralized: One main agent gives tasks to others. It puts their work together.
- Decentralized: Agents talk to each other directly. They share information and agree on things.
- Hybrid: A mix of control and teamwork. It has some central guidance and some agent talking.
AI agents can reason, plan, and act. They are used in many AI applications. Examples include coding help and health coaches. The industry is moving to longer tasks. Instead of just answering questions, agents work in steps. We need new ways to check how well agents work. Old ways only check accuracy. Agents are more complex. One error can cause more problems later. We need to know how to build the best agent systems.
People often think more agents are always better. They believe adding special agents will always help. Some studies show that more AI models improve performance. Other research found that agents working together can be smarter than one agent alone.
Our new paper, \u201cTowards a Science of Scaling Agent Systems,\u201d looks at this idea. We tested 180 different agent setups. We found rules for how agent systems get better. The idea that more agents are always better is not always true. Sometimes, too many agents can make things worse. It depends on the task.
How we tested agents
We needed to know what makes a task need an "agent." Old tests only check a model's knowledge. They don't show how well it works in real use. We say that agent tasks need three things:
- Tasks need many steps over time. The agent works with its world.
- The agent needs to find information. It doesn't know everything at first.
- The agent must change its plan. It learns from what happens in the world.
We tested five main setups. One used a single agent (SAS). Four used many agents. We tested them on different tasks. These tasks included finance help, web browsing, planning, and using tools. Here are the agent setups:
- Single-Agent (SAS): One agent does everything. It remembers things and acts step by step.
- Independent: Many agents work on their own. They don't talk to each other. They combine results at the end.
- Centralized: One main agent gives tasks to others. It puts their work together.
- Decentralized: Agents talk to each other directly. They share information and agree on things.
- Hybrid: A mix of control and teamwork. It has some central guidance and some agent talking.
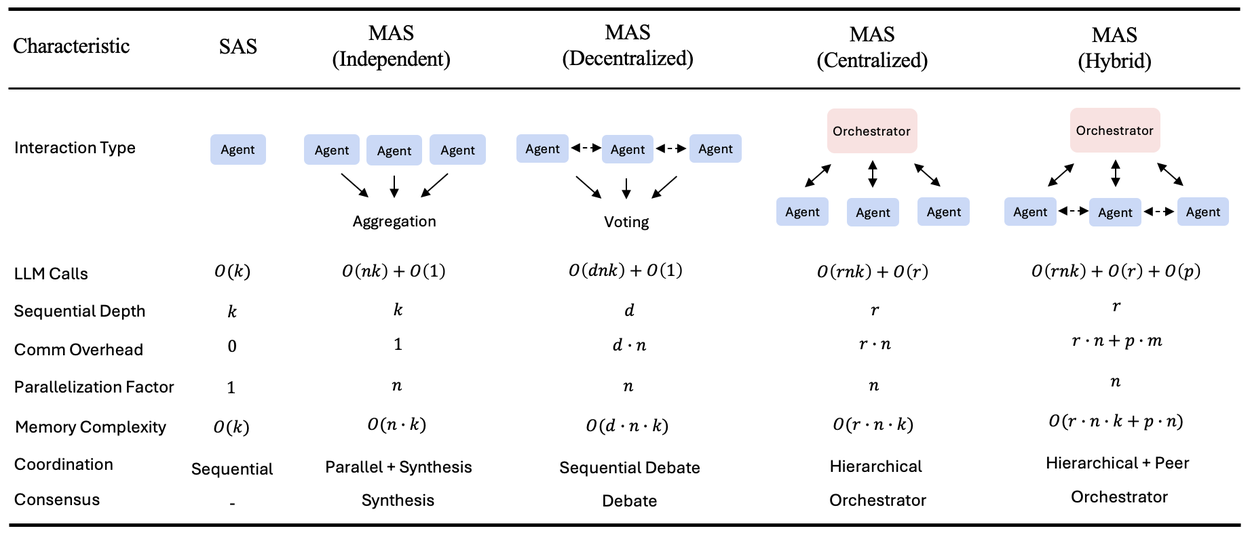
This shows the five agent setups. It includes how much work they do, how much they talk, and how they work together. k = steps per agent, n = number of agents, r = rounds for the main agent, d = rounds for talking, p = rounds for agents talking to each other, m = how many agents talk each round. Talking means sending messages between agents. Independent agents work fast with little teamwork. Decentralized agents talk in steps. Hybrid agents use a main agent and also let agents talk to each other.
What we found: The myth of "more agents"
We tested how well different AI models worked with these setups. We used models from OpenAI, Google, and Anthropic. The results show that how well agents work is tricky. It depends on the AI model and how agents work together. More agents don't always help. Sometimes, they make performance worse.
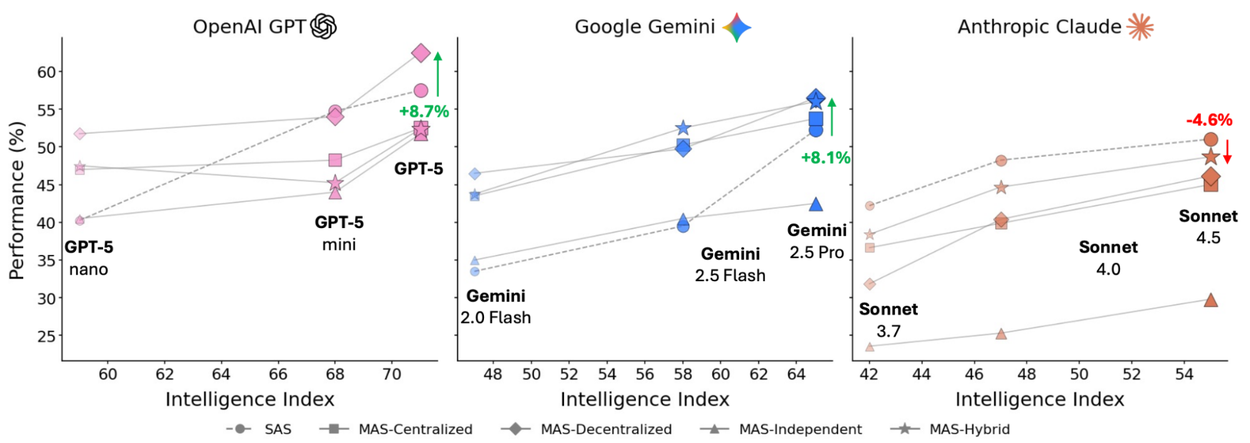
This chart compares how well different agent setups work. It uses three main AI models. It shows how agent setups change with smarter models. Working together can help, but it can also hurt performance.
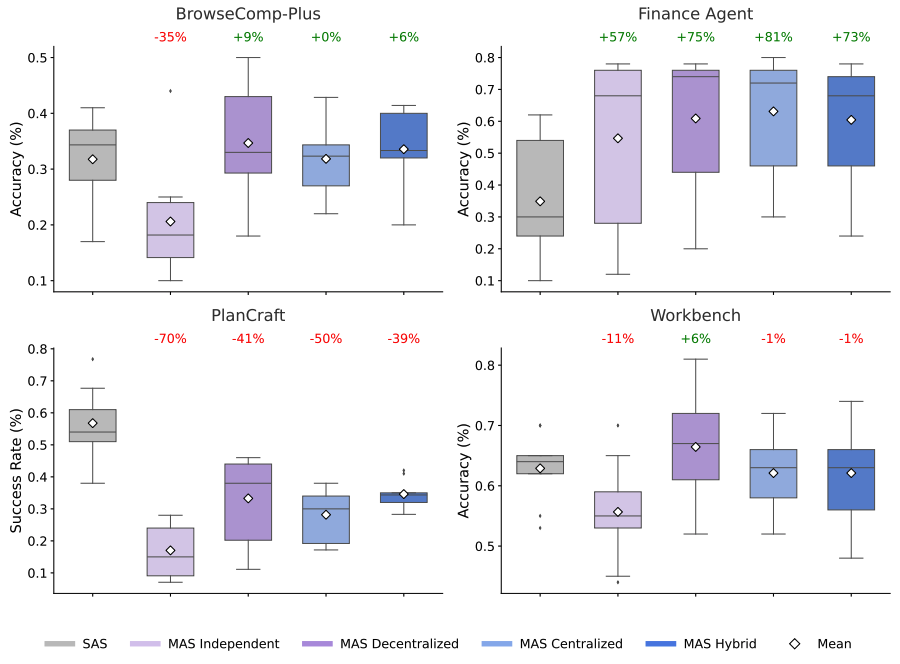
Here, we compare the setups on tasks like web browsing and finance. The charts show how well each setup works. The numbers show if many agents helped or hurt compared to one agent. Many agents help a lot on tasks that can be done at the same time. But they can be slower or make mistakes on tasks that need steps in order.
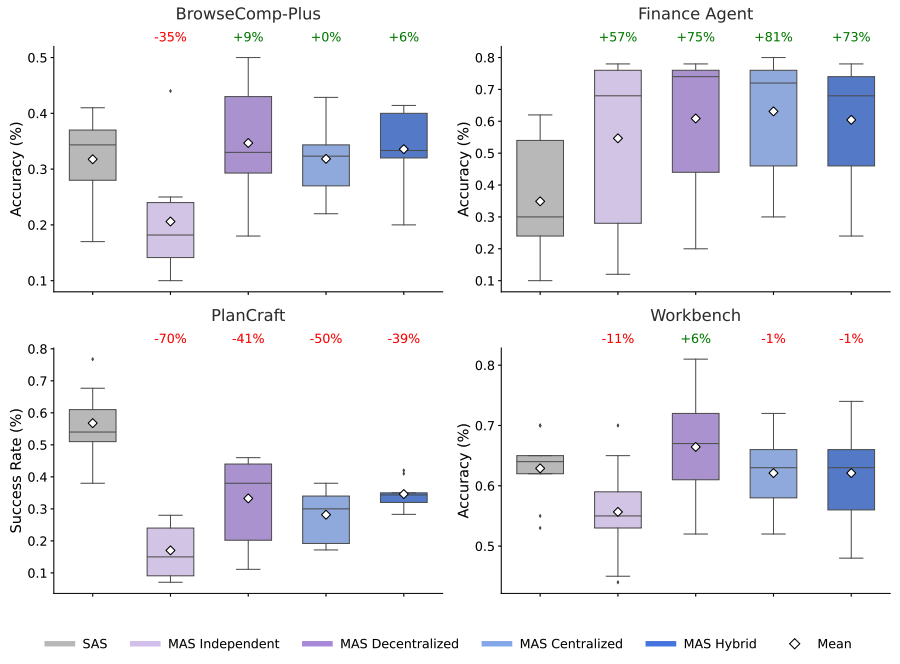
This shows how well agents do on different tasks. Working together helps a lot on tasks like finance (+81%). But it makes tasks like planning worse (-70%).
When teamwork helps
For tasks that can be split up, like looking at different money data, working together helped a lot. A setup where one agent managed others improved performance by over 80%. This is because the main agent could give different jobs to other agents. They could work on parts of the problem at the same time.
When teamwork hurts
For tasks that need steps in a specific order, like planning, many agents made things worse. All the multi-agent setups we tested made performance worse by 39% to 70%. When agents have to talk to each other a lot, it slows down the thinking. There is less time to actually do the task.
Too many tools
We found that using many tools makes things harder. If a task needs many different tools, coordinating many agents becomes much harder. This takes up too much time.
Architecture can make systems safer
How we set up the agents also affects how many mistakes they make. We looked at how errors spread from one agent to the final result.
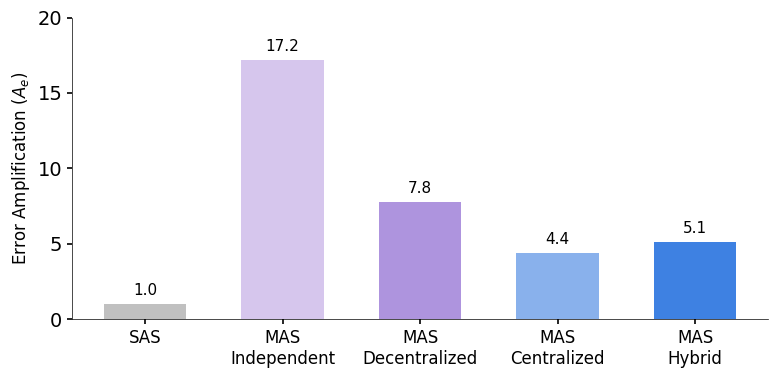
This chart shows how reliable different agent setups are. Centralized setups are best at avoiding errors. Independent agents can make errors much worse, up to 17.2 times.
Agents working alone made errors 17.2 times worse. They didn't check each other's work. Errors spread easily. With a main agent in charge, errors only got 4.4 times worse. The main agent acted like a quality check, catching mistakes.
A model to predict what works best
We created a model that can guess which agent setup will work best. It looks at how a task can be broken down and how many tools it needs. This model is right 87% of the time for new tasks. This means we can now choose the right setup for a task. We don't have to guess anymore.
We are building a science for agent systems. Before, people guessed if they should use many agents or one big model. Now, they can look at the task's features. They can choose the best way to build their AI agents.
Conclusion
AI models like Gemini keep getting better. Our research shows that better models make multi-agent systems even more important. But the way you set them up matters most. We are moving from guesses to real science. This will help us build better AI agents. They will be smarter, safer, and work better.
This shows the five agent setups. It includes how much work they do, how much they talk, and how they work together. k = steps per agent, n = number of agents, r = rounds for the main agent, d = rounds for talking, p = rounds for agents talking to each other, m = how many agents talk each round. Talking means sending messages between agents. Independent agents work fast with little teamwork. Decentralized agents talk in steps. Hybrid agents use a main agent and also let agents talk to each other.
What we found: The myth of "more agents"
We tested how well different AI models worked with these setups. We used models from OpenAI, Google, and Anthropic. The results show that how well agents work is tricky. It depends on the AI model and how agents work together. More agents don't always help. Sometimes, they make performance worse.
This chart compares how well different agent setups work. It uses three main AI models. It shows how agent setups change with smarter models. Working together can help, but it can also hurt performance.
Here, we compare the setups on tasks like web browsing and finance. The charts show how well each setup works. The numbers show if many agents helped or hurt compared to one agent. Many agents help a lot on tasks that can be done at the same time. But they can be slower or make mistakes on tasks that need steps in order.
This shows how well agents do on different tasks. Working together helps a lot on tasks like finance (+81%). But it makes tasks like planning worse (-70%).
When teamwork helps
For tasks that can be split up, like looking at different money data, working together helped a lot. A setup where one agent managed others improved performance by over 80%. This is because the main agent could give different jobs to other agents. They could work on parts of the problem at the same time.
When teamwork hurts
For tasks that need steps in a specific order, like planning, many agents made things worse. All the multi-agent setups we tested made performance worse by 39% to 70%. When agents have to talk to each other a lot, it slows down the thinking. There is less time to actually do the task.
Too many tools
We found that using many tools makes things harder. If a task needs many different tools, coordinating many agents becomes much harder. This takes up too much time.
Architecture can make systems safer
How we set up the agents also affects how many mistakes they make. We looked at how errors spread from one agent to the final result.
This chart shows how reliable different agent setups are. Centralized setups are best at avoiding errors. Independent agents can make errors much worse, up to 17.2 times.
Agents working alone made errors 17.2 times worse. They didn't check each other's work. Errors spread easily. With a main agent in charge, errors only got 4.4 times worse. The main agent acted like a quality check, catching mistakes.
A model to predict what works best
We created a model that can guess which agent setup will work best. It looks at how a task can be broken down and how many tools it needs. This model is right 87% of the time for new tasks. This means we can now choose the right setup for a task. We don't have to guess anymore.
We are building a science for agent systems. Before, people guessed if they should use many agents or one big model. Now, they can look at the task's features. They can choose the best way to build their AI agents.
Conclusion
AI models like Gemini keep getting better. Our research shows that better models make multi-agent systems even more important. But the way you set them up matters most. We are moving from guesses to real science. This will help us build better AI agents. They will be smarter, safer, and work better.