


Large language models (LLMs) demonstrate significant potential for medical and health question-answering across diverse tests and data sources. Our pioneering work, including Med-Gemini, MedPaLM, AMIE, Multimodal Medical AI, and novel evaluation tools, expands LLM utility in healthcare. Especially in low-resource regions, LLMs can empower clinical decision-support systems, improving diagnostic accuracy, accessibility, and multilingual clinical guidance, alongside community health training. However, current LLMs face challenges generalizing to tasks with distribution shifts in disease types, region-specific knowledge, and variations in symptoms, language, location, linguistic diversity, and local cultural contexts.
Tropical and infectious diseases (TRINDs) represent a critical out-of-distribution disease subgroup. TRINDs disproportionately affect the world's poorest regions, impacting 1.7 billion people, particularly women and children. Challenges in prevention and treatment stem from limitations in surveillance, early detection, accurate diagnosis, management, and vaccine development. LLMs can facilitate early screening and surveillance using symptoms, location, and risk factors. Yet, LLM performance on TRINDs remains understudied, with few rigorous evaluation datasets available.
To bridge this gap, we developed synthetic personas—datasets for evaluating and optimizing models—and benchmarking methodologies for out-of-distribution disease subgroups. Our TRINDs dataset comprises over 11,000 manually and LLM-generated personas covering a wide spectrum of tropical and infectious diseases, augmented with demographic, contextual, location, language, clinical, and consumer variations. This research was recently presented at the NeurIPS 2024 workshops on Generative AI for Health and Advances in Medical Foundation Models.
TRINDs dataset development and benchmarking overview.
Develop Synthetic TRINDs Personas for Robust LLM Evaluation
We meticulously analyzed authoritative sources like the WHO, PAHO, and CDC to gather factual disease information. This informed the creation of initial patient persona templates for each disease, detailing general symptoms, direct attributes, and specific symptoms. These personas also incorporate context, lifestyle, and risk factors, all validated by clinicians for accuracy and relevance. Our current seed personas cover 50 distinct diseases.
Building blocks for the TRINDs dataset.
We employed LLM prompting to expand the initial persona set with demographic, clinical, and consumer augmentations, generating over 11,000 personas. Furthermore, we translated the seed set into French to assess LLM performance shifts due to language variations. We then developed an LLM-based autorater that validates an answer by checking if the ground truth and predicted diagnosis are identical or substantially similar.
Examples of an original seed persona and LLM-augmentations.
LLM Evaluation: TRINDs Performance Versus USMLE Standards
We evaluated Gemini models (Gemini 1.5) on their accuracy in identifying diseases from persona descriptions. Our results reveal significant performance distribution shifts compared to USMLE-based benchmark datasets, with notably lower accuracy on the TRINDs set than previously reported for US datasets.
Contextual Relevance Significantly Impacts Diagnostic Accuracy
We systematically evaluated the dataset to understand how various contexts, types (clinical vs. consumer), demographics, and semantic styles affect LLM performance. Our findings show that combining symptoms, risk factors, location, and demographics yields the highest accuracy, underscoring that symptoms alone are insufficient for precise diagnoses.
Model performance on contextual combinations of symptoms (general and specific), location, risk factors, and demographic attributes. S = symptoms, L = location, A = attributes, R = risk factors, gS = general symptoms, sS = specific symptoms, FP = full persona with all context. Error bars = 95% confidence interval. Note: FP accuracy is also significantly higher than S, SA and gSLAR.
Performance Across Race, Gender, and Counterfactual Locations
We investigated the impact of including explicit racial identifiers (e.g., "I am Black") and variations in gendered language (female, male, non-binary) on LLM performance. Our analysis revealed no statistically significant performance differences across race and gender. We also examined the effect of specifying low-incidence locations (counterfactual locations) on performance, detailed in our paper.
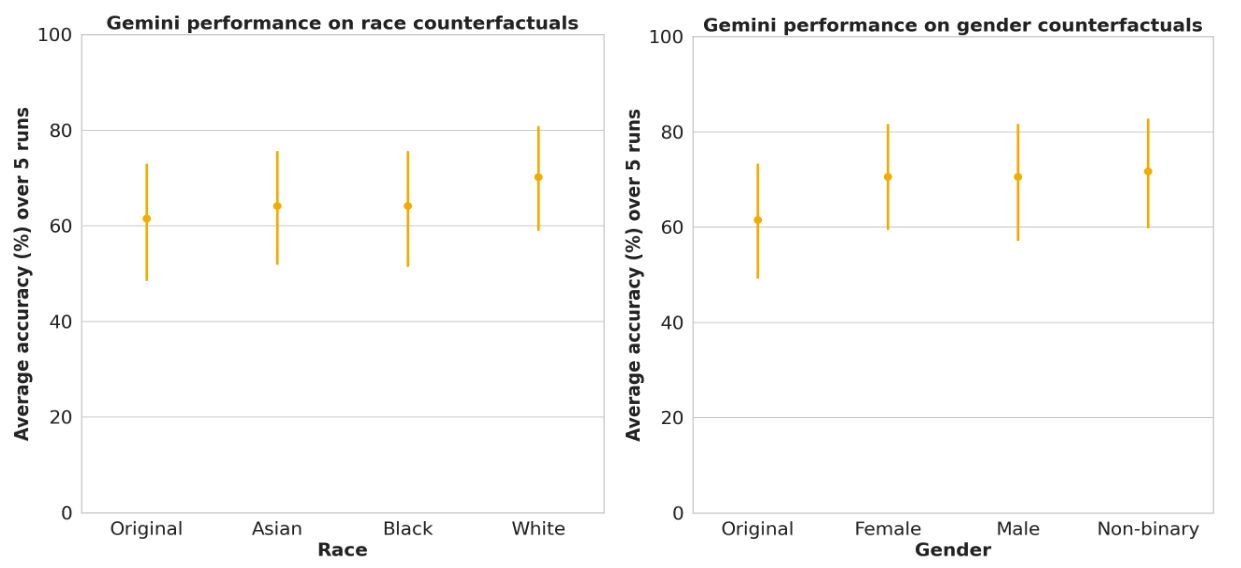
LLM performance on race and gender subgroups in TRINDs demonstrate no significant differences. Error bars = 95% confidence interval.
Human Expert Performance Benchmarking
We engaged seven TRINDs and public health experts with over a decade of experience to answer short-answer and multiple-choice questions. We characterized the performance of the top five experts and subsequently measured LLM performance on the same data subset, enabling a simulation of various expert roundtable scenarios.
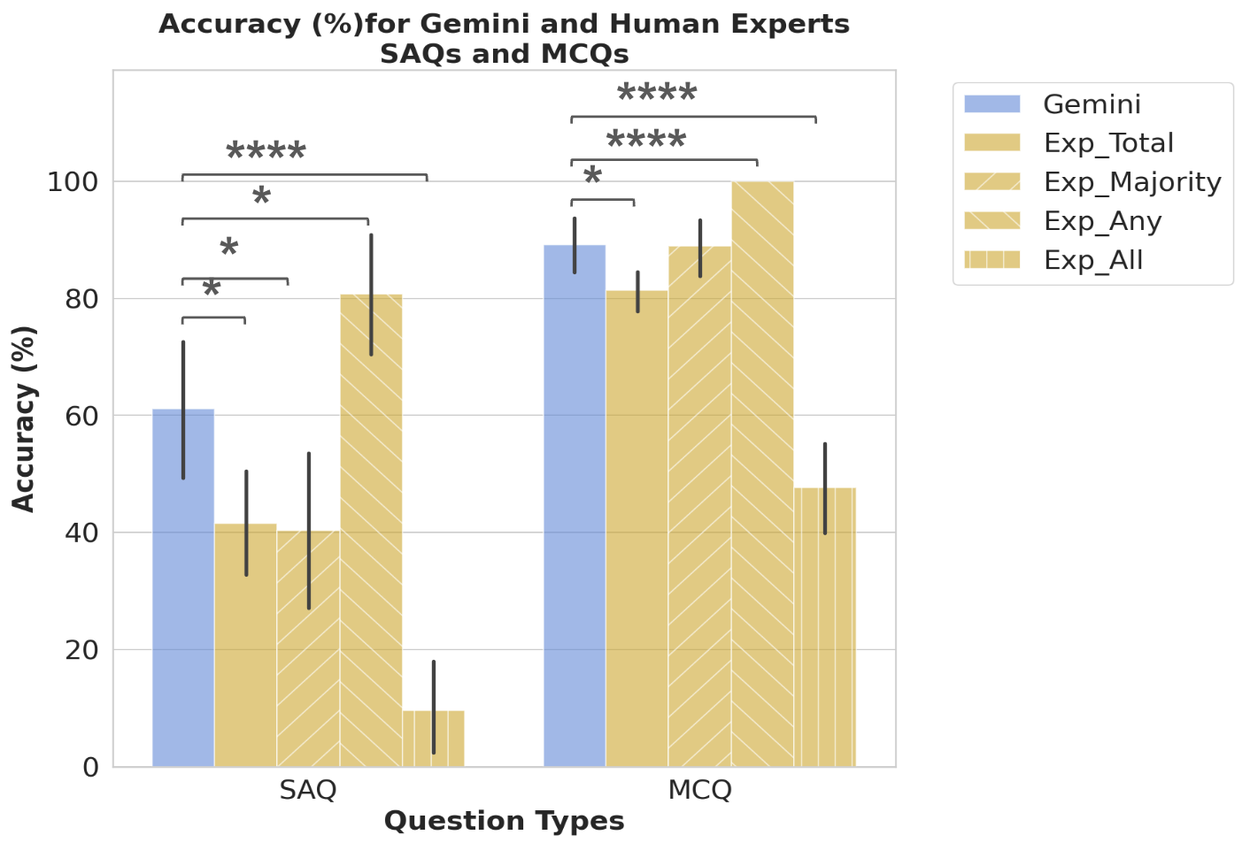
Comparison of LLM (Gemini) performance to that of the the top five experts, which were characterized with four scores: 1) the average across the total expert score (Exp_Total); 2) the full score if the majority vote was correct (Exp_Majority); 3) the full score if any expert was correct (Exp_Any); and 4) the full score only if all experts were correct (Exp_All), allowing us to explore a variety of expert decision making scenarios. Error bars = 95% confidence interval.
Although LLMs underperformed on TRINDs compared to USMLE benchmarks, they surpassed the top-performing expert and most expert combination scenarios. The exception is the Exp_Any scenario, representing a roundtable of public health experts with diverse specializations, which serves as a more appropriate benchmark to exceed.
Per-Disease Performance Analysis
LLMs demonstrate higher accuracy in identifying common diseases (e.g., HIV) or those with distinct symptoms and risk factors (e.g., rabies). However, diseases like tapeworm infection may be misidentified when only symptoms are provided. Rabies, conversely, shows greater robustness to counterfactual locations.
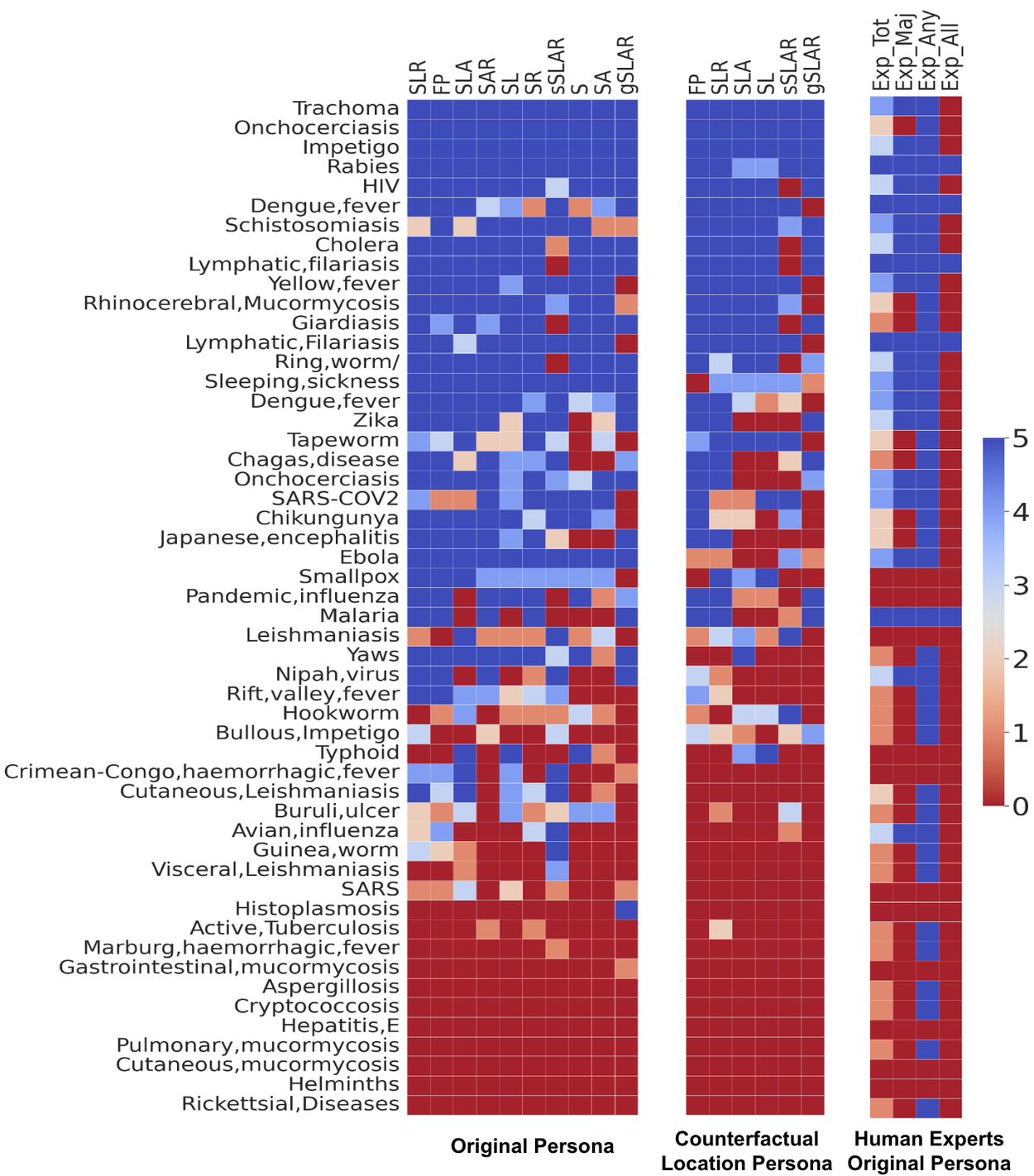
Per disease performance of the LLM on tropical and infectious diseases shown with different contextual combinations (left), contextual combinations with location counterfactual (center), and the human expert performance (right). Contextual combinations abbreviated as above.
Enhance LLM Performance via In-Context Learning
We fine-tuned Gemini 1.5 using in-context learning with simple multi-shot prompting on the seed set of 50 questions (one per disease), incorporating all symptoms, locations, and risk factors. This optimization significantly improves performance on both demographic and semantic augmentations, proving that intentional tuning rectifies performance gaps and that seed datasets effectively optimize LLM capabilities.
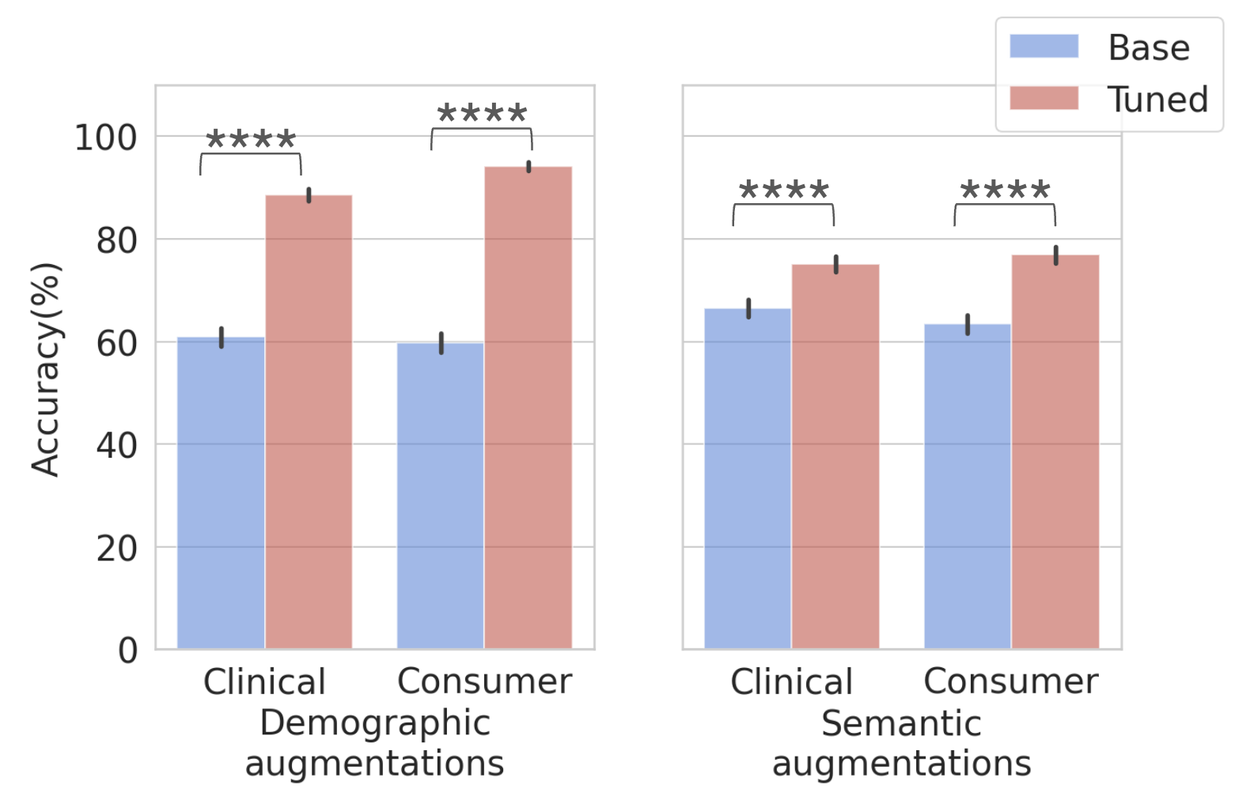
Performance on demographic (left) and semantic (right) augmented datasets before and after in-context tuning. Total = 10,570, clinical demographic (n=2635), consumer demographic (n=2635), clinical semantic (n=2650) and consumer semantic (n=2650). Error bars = 95% confidence interval.
Assess LLM Potential for Disease Screening Tools
We developed a TRINDs disease screening user interface, powered by a fine-tuned Gemini model. This interface allows users to input demographics, location, lifestyle, and risk factors, select symptoms from a comprehensive list, and receive a diagnosis. We integrated the tool with the Our World in Data API to display real-time incidence rates.
User interface and use case of LLM-based tool for tropical and infectious disease screening.
Early expert ratings indicate that this interface, despite its straightforward output, possesses the potential to become a highly impactful and user-friendly reference tool for infectious diseases, benefiting both clinicians and researchers.
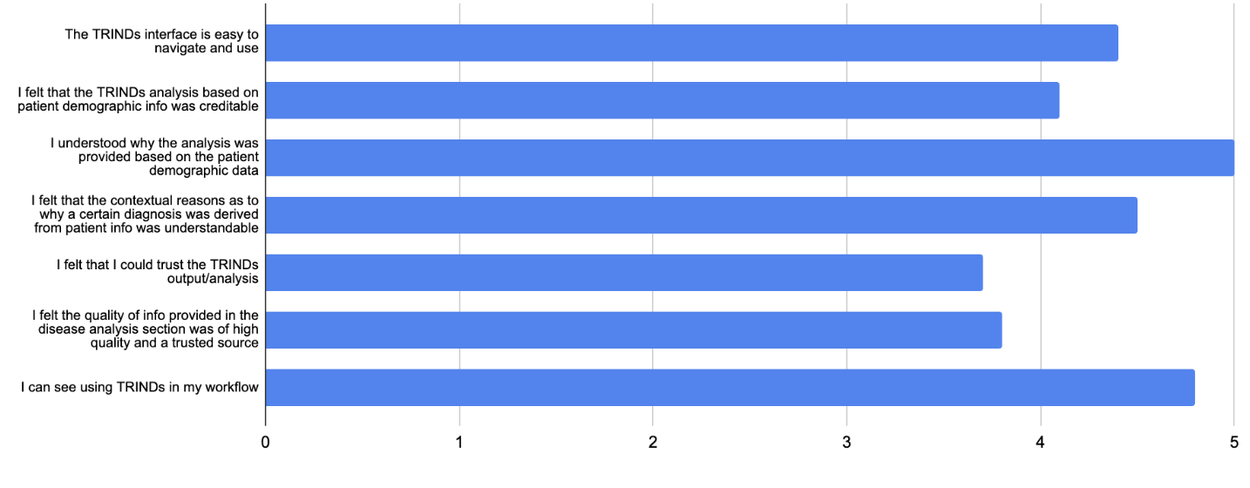
Expert ratings of TRINDs tool.
Key Implications for Global Health
Our findings underscore the significant potential of LLM-based tools to support healthcare workers in resource-limited settings. Crucially, these tools must augment, not replace, clinical judgment. They require continuous assessment, regular updates to reflect evolving real-world scenarios, and proven reliability across diverse clinical environments. Given the critical nature of health outcomes, LLMs must demonstrate accurate, contextual, and culturally relevant performance. Translating this approach into a clinical tool necessitates rigorous further validation and adherence to standard regulatory review processes. Future research will expand benchmarks to include multilinguality and multimodality.