


Hundreds of millions of people leverage large language model (LLM) chatbots daily for diverse tasks, from drafting emails and coding to planning travel and designing menus. Understanding these high-level use cases provides invaluable insights for platform providers aiming to enhance services or enforce safety policies, while also offering the public a window into AI's societal impact.
This capability, however, introduces a critical challenge: How can we extract valuable insights from conversations that may contain private or sensitive information?
Current solutions, such as the CLIO framework, attempt to address this by employing an LLM to summarize conversations, prompting it to remove personally identifiable information (PII). While a commendable initial step, this method relies on heuristic privacy protections. The resulting privacy guarantee lacks formalization and may falter as models evolve, complicating system maintenance and auditing. This limitation prompted our investigation into achieving comparable utility with formal, end-to-end privacy guarantees.
In our paper, "Urania: Differentially Private Insights into AI Use," presented at COLM 2025, we introduce a groundbreaking framework that generates insights from LLM chatbot interactions with robust differential privacy (DP) guarantees. Our framework utilizes a DP clustering algorithm and keyword extraction method, ensuring that no single conversation disproportionately influences the output. This prevents the revelation of information specific to any individual's conversation. Here, we detail the algorithm and demonstrate its superior privacy guarantees compared to previous solutions.
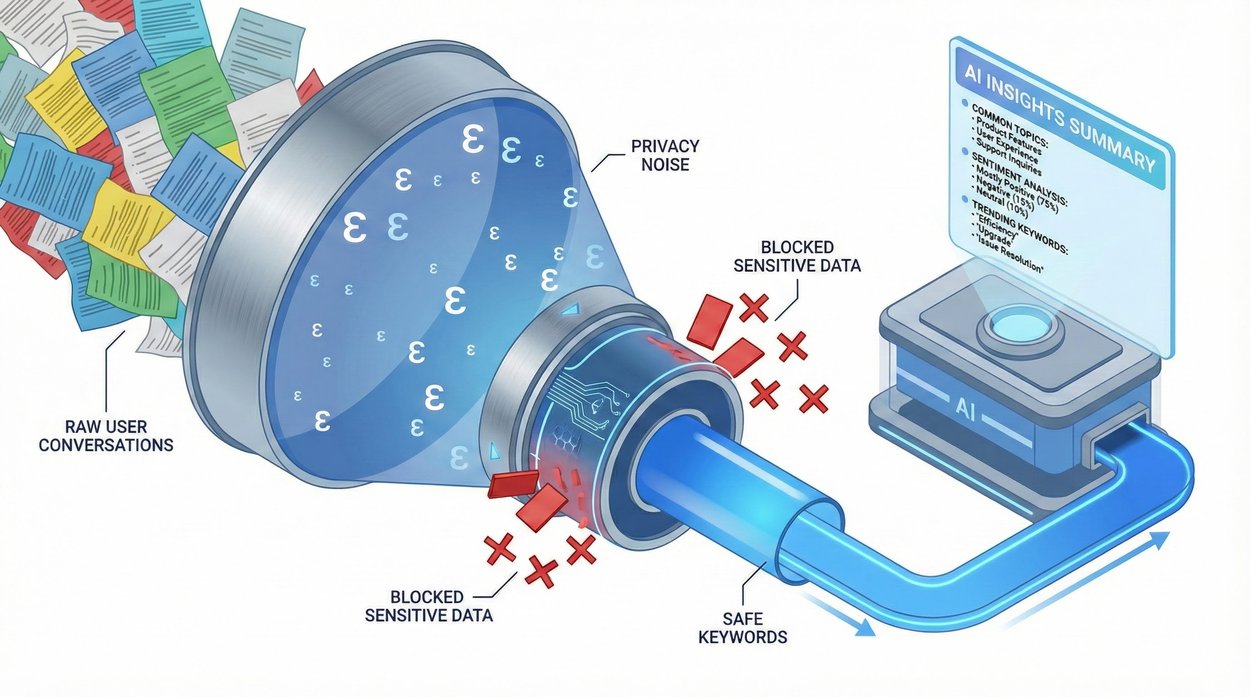
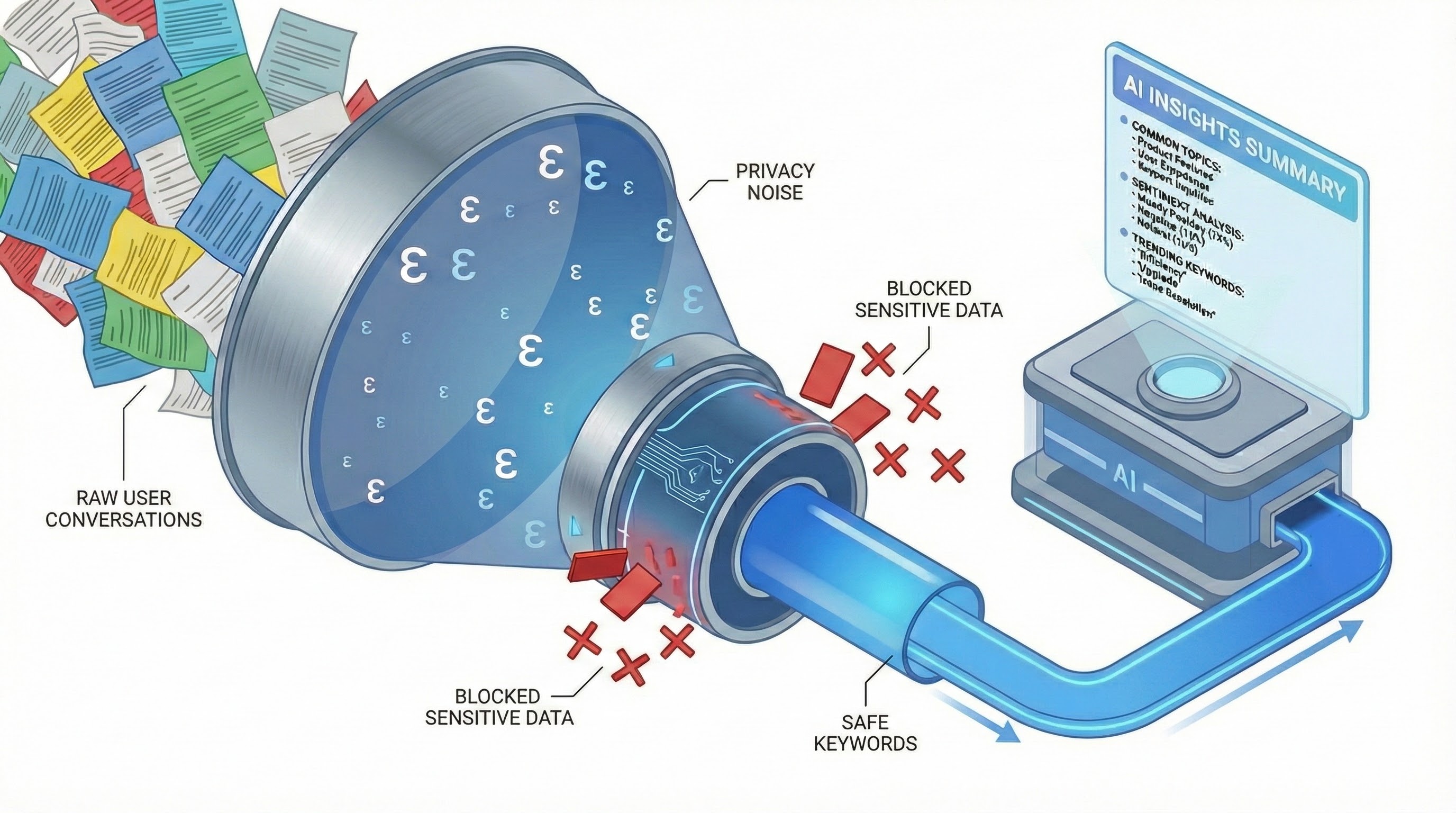
Gemini-generated image illustrating the algorithm's operation for a conversation cluster.
Achieve Privacy-Preserving Insights Mining
Differential privacy (DP) quantifies the maximum influence any single user's data can have on a model's output using a privacy budget parameter, ε. Our framework leverages two fundamental DP properties:
- Post-processing: Applying any non-DP algorithm (A) to the output of an ε-DP algorithm (B) maintains the ε-DP level of privacy.
- Composition: Executing two separate ε-DP algorithms (A and B) on a dataset, and then running A on the dataset and B's output, results in a 2ε-DP privacy level for the entire process.
This robust differentially private pipeline ensures end-to-end user data protection through the following stages:
- DP Clustering: Conversations are initially transformed into numerical representations (embeddings). The framework then employs a DP clustering algorithm to group similar representations, ensuring cluster centers are not overly influenced by any single conversation.
- DP Keyword Extraction: Keywords are extracted from each conversation. For every cluster, our method calculates a keyword histogram using a DP histogram mechanism. This process adds noise to mask individual conversation influence, guaranteeing that only keywords common to multiple users are selected, thereby preventing the exposure of unique or sensitive terms. We explore three keyword generation methods: LLM-guided selection of top keywords, a DP version of TF-IDF weighting, and an LLM selection from a pre-defined keyword list derived from public data.
- LLM Summarization from Keywords: Finally, an LLM generates a high-level summary for each cluster using exclusively the privately extracted keywords. The LLM never accesses original conversations, ensuring end-to-end privacy through this post-processing step.
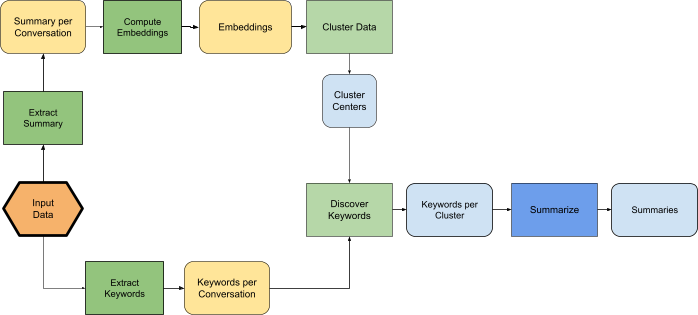
The framework's data flow visualizes DP operations. Yellow indicates non-DP data, green denotes DP or per-conversation operations, light blue signifies private data, and dark blue represents non-private operations.
By embedding DP at its core, this framework provides mathematical privacy guarantees, moving beyond heuristic protections. This ensures that even if keywords inadvertently contain PII, the generated summaries will not. This formal guarantee effectively prevents LLMs from revealing sensitive data, even under adversarial conditions like prompt injection attacks.
Test the Privacy-Preserving Framework
We evaluated our framework's utility (summary quality) and privacy (protection strength) by comparing it against Simple-CLIO, a non-private baseline we developed inspired by CLIO. This baseline operates in two stages: non-private clustering of conversation embeddings, followed by an LLM summarizing a sample of conversations from each cluster.
Navigating the Privacy-Utility Trade-off
As anticipated, we observed a trade-off: heightened privacy settings (lower ε values) reduced summary granularity. Topic coverage diminished with tighter privacy budgets because the DP clustering algorithm produced fewer, less precise clusters. Surprisingly, LLM evaluators frequently favored the private summaries generated by our framework in direct comparisons, sometimes up to 70% of the time. This suggests that the DP pipeline's constraints, which prioritize general, frequent keywords, yield outputs that are more concise and focused than those from unconstrained, non-private approaches.
Empirical Privacy Evaluation
To rigorously test the framework's robustness, we implemented a membership inference-style attack to detect the inclusion of specific sensitive conversations within the dataset. The DP pipeline proved highly effective, performing comparably to random guessing with an area under the curve (AUC) score of 0.53. In contrast, the non-private pipeline exhibited greater information leakage, achieving a higher AUC of 0.58. This empirical evidence strongly supports our privacy framework's significantly enhanced protection against privacy leakage.
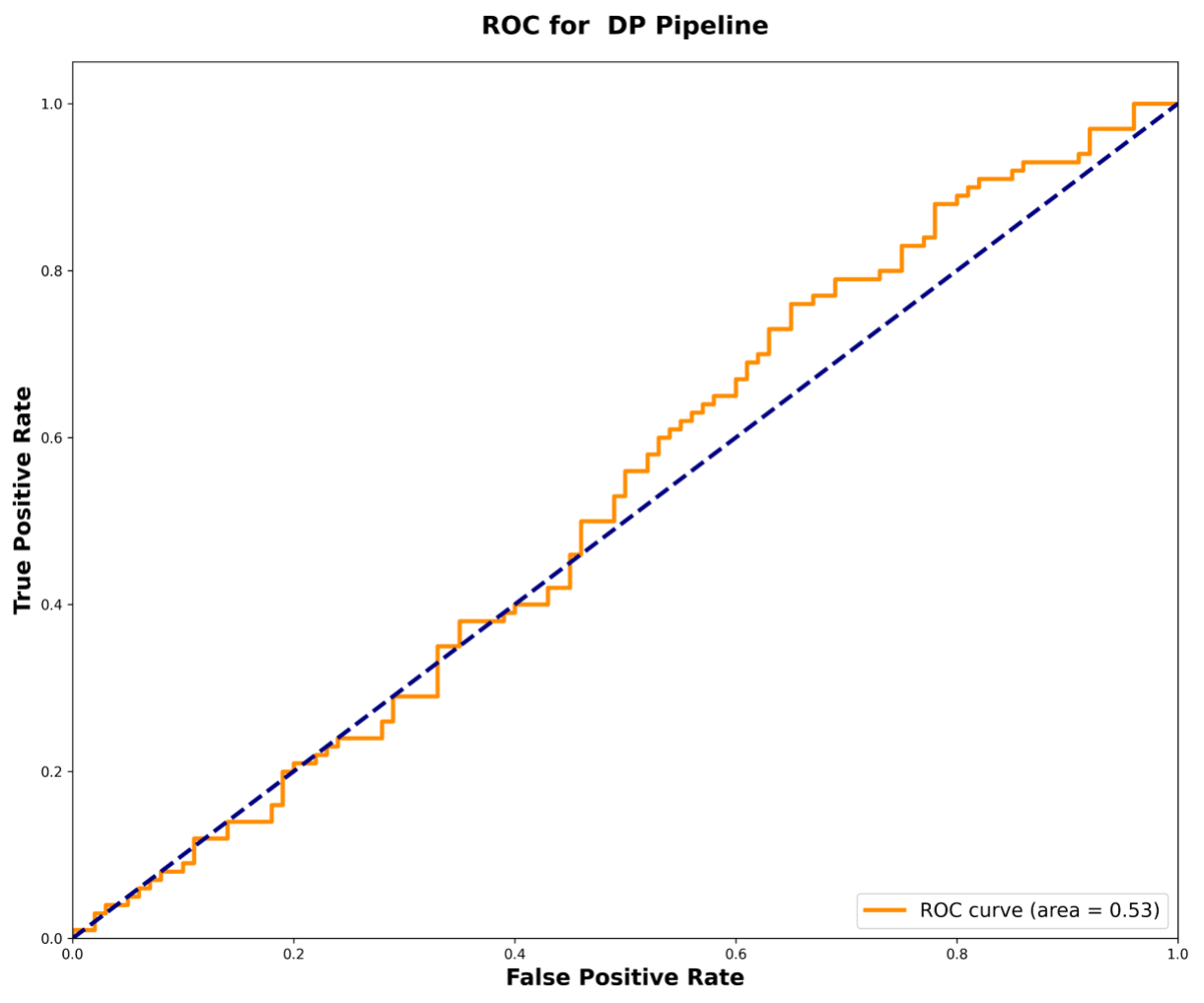
The ROC curve for the DP pipeline demonstrates performance near random guessing (AUC = 0.53), highlighting its robust privacy protection.
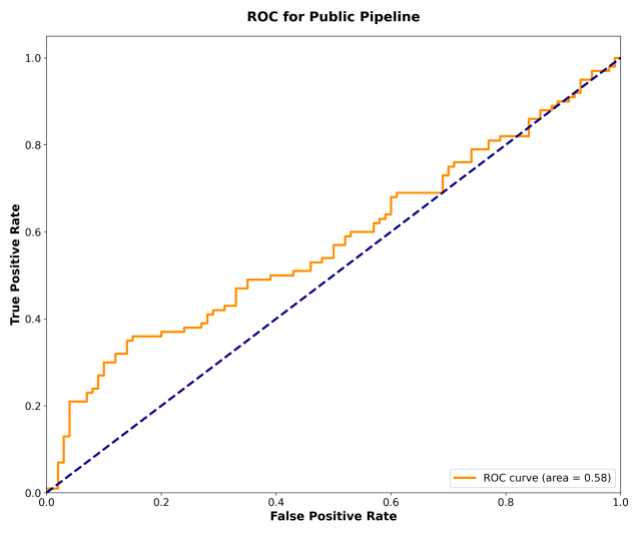
The ROC curve for the non-private pipeline shows increased vulnerability (AUC = 0.58).
Future Directions
Our research marks a significant initial step toward developing systems capable of analyzing large-scale text corpora while maintaining formal privacy guarantees. We have successfully demonstrated the possibility of balancing the demand for meaningful insights with stringent user privacy requirements.
Several promising avenues for future research emerge from this work. These include adapting the framework for online settings with continuous data streams, exploring alternative DP mechanisms to further optimize the privacy-utility trade-off, and incorporating support for multi-modal conversations involving images, videos, and audio.
As AI increasingly permeates our daily lives, creating privacy-preserving methods to understand its application is not merely a technical pursuit—it is an essential prerequisite for building trustworthy and responsible AI systems.
Acknowledgments
We extend our sincere gratitude to all project contributors whose pivotal efforts were instrumental to its success. Special thanks are due to our colleagues: Yaniv Carmel, Edith Cohen, Rudrajit Das, Chris Dibak, Vadym Doroshenko, Alessandro Epasto, Prem Eruvbetine, Dem Gerolemou, Badih Ghazi, Miguel Guevara, Steve He, Peter Kairouz, Pritish Kamath, Nir Kerem, Ravi Kumar, Ethan Leeman, Pasin Manurangsi, Shlomi Pasternak, Mikhail Pravilov, Adam Sealfon, Yurii Sushko, Da Yu, Chiyuan Zhang.