



Leveraging large, user-based datasets fuels AI and machine learning innovation, delivering improved services, accurate predictions, and personalized user experiences. Collaborative data sharing accelerates research and fosters new applications. However, this powerful data utilization carries inherent privacy risks. Differentially private (DP) partition selection identifies unique items from vast collections based on their prevalence across contributions, such as common words in extensive document sets. Applying DP to partition selection ensures that no single individual's data can be identified within the selected items, achieved by adding controlled noise and selecting only sufficiently common items post-noise. DP partition selection is a critical first step in many vital data science and machine learning tasks. These include extracting vocabulary and n-grams from private corpora for textual analysis and language modeling, analyzing data streams privately, generating histograms over user data, and boosting efficiency in private model fine-tuning.
For massive datasets like user queries, parallel algorithms are essential. Unlike sequential algorithms that process data item by item, parallel algorithms divide problems into smaller, simultaneous computations across multiple processors. This parallelization is not merely an optimization; it's fundamental for handling modern data scales, enabling the processing of billions of data points and ensuring robust privacy guarantees without sacrificing data utility.
Our publication, “Scalable Private Partition Selection via Adaptive Weighting,” presented at ICML2025, introduces an efficient parallel algorithm for DP partition selection in diverse data releases. This algorithm achieves superior results compared to existing parallel methods and scales to datasets with hundreds of billions of items—up to three orders of magnitude larger than those processed by prior sequential algorithms. To promote research and innovation, we have open-sourced our DP partition selection implementation on GitHub.
Revolutionize Your Data Privacy: Advanced DP Partition Selection
The core objective of DP partition selection is to maximize the selection of unique items from a combined dataset while rigorously maintaining user-level differential privacy. This approach safely includes highly prevalent items, common across many users, for subsequent computational tasks, while excluding items unique to a single user. Algorithm designers must expertly balance privacy and utility, ensuring optimal item selection under strict differential privacy requirements.
Master the Standard: Weight, Noise, Filter Paradigm
The established differentially private partition selection method employs three fundamental steps: First, compute a "weight" for each item, typically reflecting its frequency or aggregation across users, creating a weight histogram. Crucially, items must exhibit "low sensitivity"—meaning a single user's contribution to the total weight is bounded. Non-adaptive settings, such as the Gaussian weighting baseline, have users contribute weights independently of others. Second, add random noise (e.g., Gaussian noise with a defined standard deviation) to each item's weight to ensure DP by obscuring exact counts and preventing individual inference. Third, apply a threshold determined by DP parameters; only items with noisy weights exceeding this threshold are included in the final output.
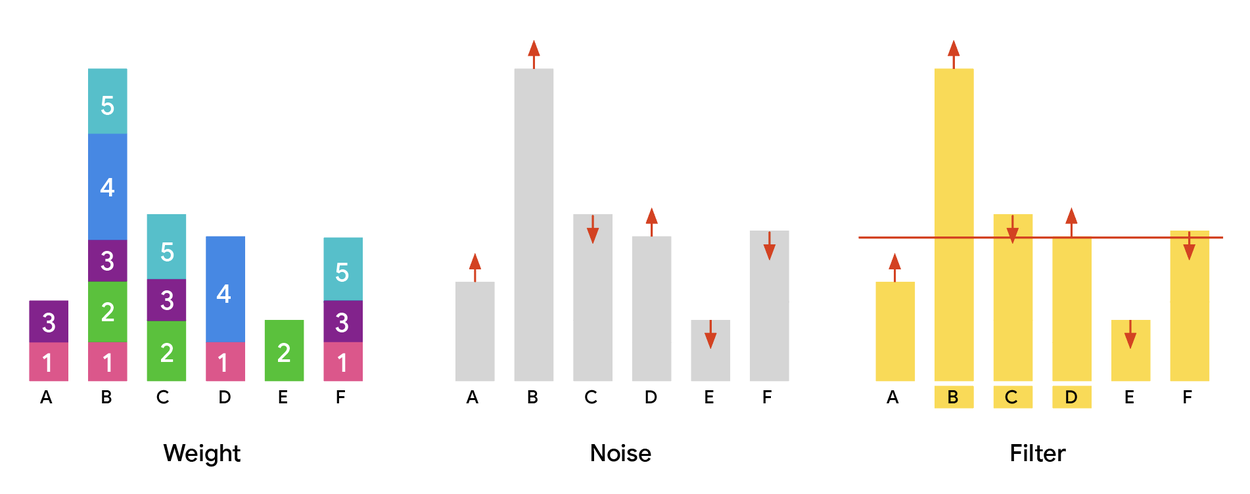
The weight, noise, and filter paradigm visually represented. All plots show items (A–F) on the x-axis and their assigned weight on the y-axis. The process starts with computing a weight histogram (left), adds noise (center), and finally selects items exceeding a defined threshold (right).
Maximize Utility with Adaptive Weighting
A key limitation of standard, non-adaptive approaches is "weight wastage." Highly popular items might receive weights far exceeding the privacy threshold, unnecessarily consuming potential utility. This surplus weight could be more effectively redistributed to items just below the threshold, increasing the total number of released items and enhancing output utility.
We introduce adaptivity to the weight assignment process. Unlike non-adaptive methods where user contributions are independent, adaptive designs allow an item's weight to incorporate input from other users. This dynamic adjustment must be carefully managed to preserve privacy and computational efficiency.
Our innovative MaxAdaptiveDegree (MAD) algorithm strategically reallocates weight. It identifies items with significant "excess weight" (well above the threshold) and redirects some of that weight to "under-allocated" items (those just below the threshold). This adaptive reallocation boosts the inclusion of less frequent items by helping them cross the privacy threshold. Crucially, MAD maintains the same low-sensitivity bounds and efficiency as baseline methods, offering equivalent strong privacy guarantees and scalability in parallel processing frameworks like MapReduce, but with demonstrably superior utility.
We further extend this adaptive concept to multi-round DP partition selection frameworks. By safely releasing intermediate noisy weight vectors between rounds, we enable greater adaptivity. This allows for reduced future weight allocations to items that previously received excessive or insufficient weight, refining the distribution and maximizing utility without compromising privacy. This further increases the number of items in the final output.
Empirical Validation: Demonstrating Superior Performance
We conducted extensive experiments, benchmarking our MAD algorithm (with one or multiple iterations) against scalable baselines for private partition selection.
The results, presented in the table below, highlight that MAD with just two iterations (MAD2R) achieves state-of-the-art performance across numerous datasets. It consistently outputs significantly more items than other methods—even those employing more rounds—while upholding identical privacy guarantees.
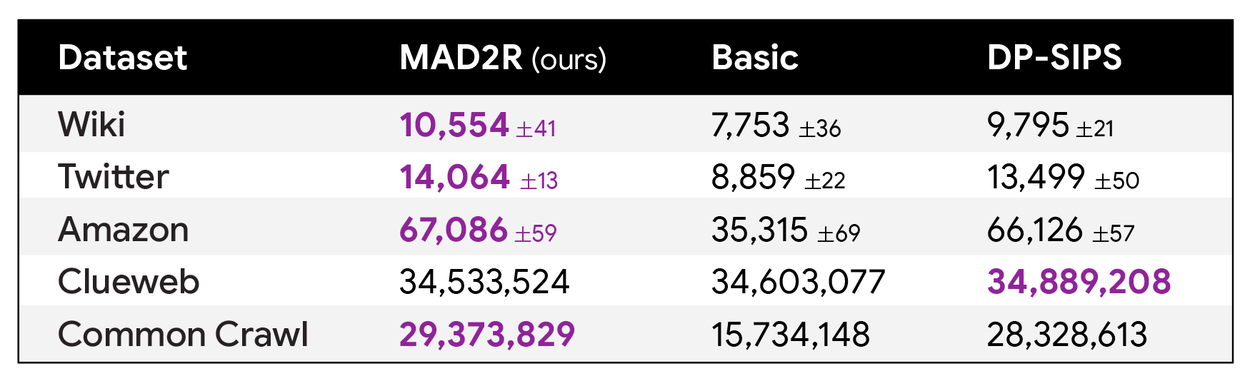
Comparative analysis of returned items by our two-round MAD2R algorithm and baseline methods: “Basic” (uniform weighting) and DP-SIPS. Leveraging advanced adaptivity techniques, our two-round algorithm sets new state-of-the-art results across many datasets.
Our comprehensive paper details theoretical findings confirming MAD's superior performance over the single-round Gaussian weighting baseline. These empirical results validate our theoretical hypotheses. The exceptional performance of our novel methods is consistent across a wide spectrum of privacy parameters and hyperparameter configurations. An in-memory Python implementation of our algorithm is readily available within the open-source repository.
On the massive Common Crawl dataset (nearly 800 billion entries), we achieved unprecedented DP levels by treating entries as "users" and their constituent words as items. Our two-iteration MAD algorithm successfully returned a set of items covering 99.9% of entries (each containing at least one selected item) and 97% of the database entries (where an item is present in the output), all while satisfying stringent DP guarantees.
With only two iterations, our algorithm consistently outperformed baselines across diverse parameter settings, aligning perfectly with our theoretical predictions and establishing new state-of-the-art benchmarks.
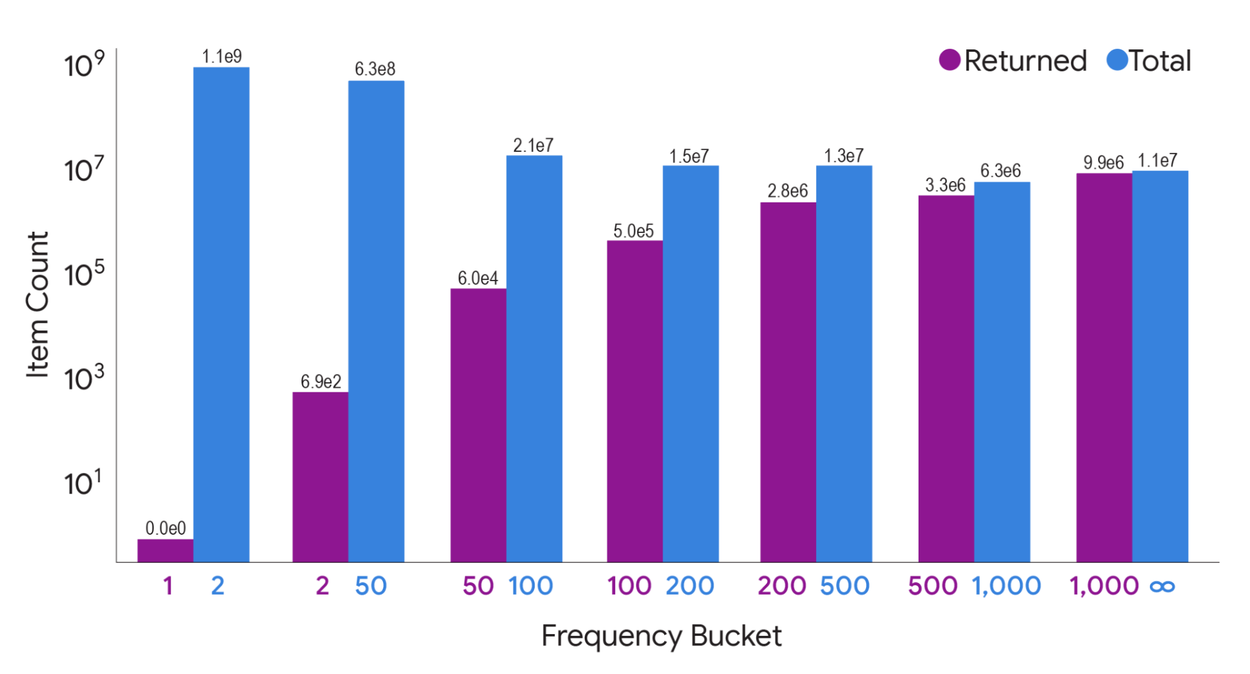
The number of items returned by our two-iteration MAD algorithm, categorized by frequency count (number of entries containing the item) on the Common Crawl dataset. While MAD prioritizes privacy by excluding low-frequency items, it successfully outputs the vast majority of items prevalent across numerous entries.
Achieve Peak Utility with Uncompromised Privacy: Conclusion
We introduce groundbreaking methods that significantly enhance the utility-privacy trade-off in differentially private partition selection algorithms. Our algorithm achieves state-of-the-art results on datasets approaching a trillion entries. We anticipate this advancement will empower practitioners to achieve higher utility across their workflows while maintaining strict user privacy standards.