



Modern machine learning (ML) achieves unprecedented performance by processing increasingly massive and complex datasets. From large language models (LLMs) to computer vision systems, handling enormous data volumes presents a significant, expensive challenge. This necessitates subset selection—choosing a smaller, representative data group from the full dataset for typical training tasks. The critical question becomes: how do we guarantee this subset contains sufficient information to train an accurate model? At NeurIPS 2025, we unveiled Greedy Independent Set Thresholding (GIST), a groundbreaking algorithm that balances data diversity and utility. GIST ensures selected data is not redundant while remaining relevant and useful for the task, outperforming state-of-the-art benchmarks with provable guarantees on solution quality.
The Challenge: Why Smart Sampling is Difficult
Selecting an optimal data subset requires balancing two often conflicting objectives: diversity and utility. Data diversity guarantees that selected points are not redundant, while utility measures the overall usefulness or informational value of the subset. For diversity, we maximize the minimum distance between any two selected data points in embedding space, known as max-min diversity. Selecting highly similar points (e.g., identical dog images) yields low diversity; max-min diversity forces selection of maximally distant points, ensuring broad data coverage. For utility, we employ monotone submodular functions to maximize unique information covered. Combining these goals proves challenging: a pure max-min strategy might select diverse but irrelevant data, while a pure utility strategy could choose a tightly clustered, redundant set. Finding a subset that is maximally spread out and maximally informative is an NP-hard combinatorial problem, rendering efficient, perfect solutions impossible for massive datasets. This inherent conflict demands a sophisticated approximation strategy.
How GIST Achieves Optimal Sampling
Since a perfect subset is impractical, the focus shifts to algorithms with provable approximation guarantees—mathematical assurances of solution quality. GIST delivers this breakthrough by systematically addressing the diversity–utility challenge through a series of simpler, interconnected optimization problems.
1. Thresholding the Diversity Component
GIST initially isolates the diversity component. Instead of tackling the complex maximization of minimum distance between all points, GIST poses a simpler question: "For a given minimum distance, what is the optimal data subset?" By fixing the required minimum distance, GIST processes data within a graph where connected points are considered too similar for the final subset. This simplifies the problem by focusing on nodes whose distance exceeds the specified threshold.
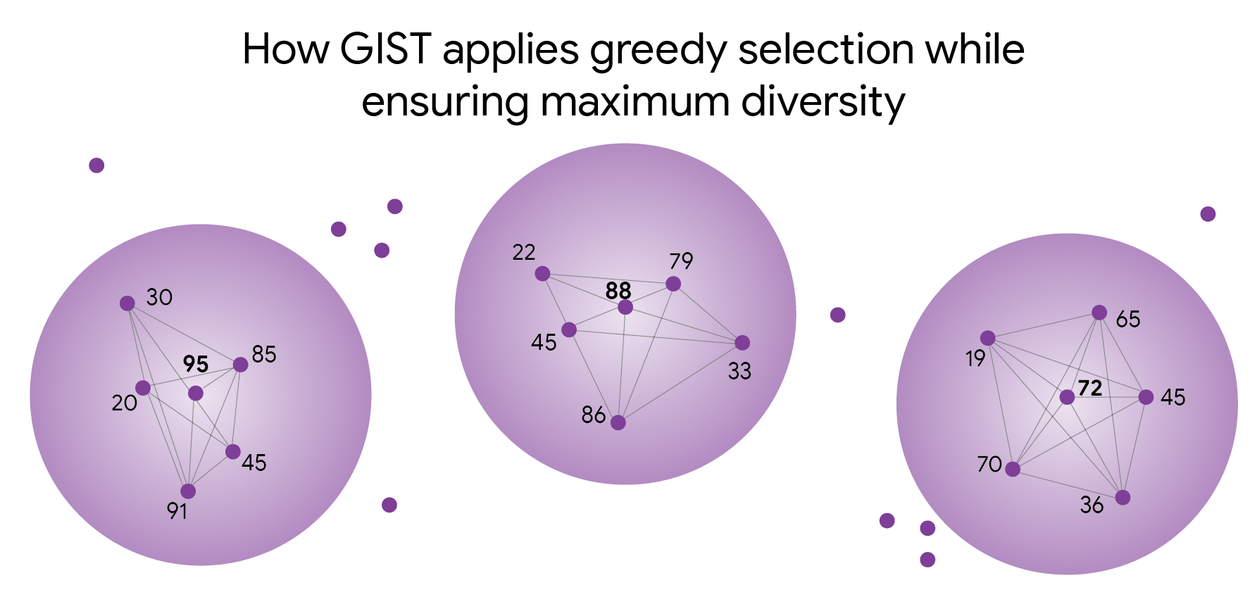
GIST identifies the highest-scoring points not within another selected point's exclusion zone, ensuring a diverse and high-quality selection. Higher numbers indicate greater data value for learning.
2. Approximating the Independent Set
Next, GIST seeks the maximum-utility subset where no two points are connected in the graph, addressing the classic maximum independent set problem. This is akin to solving a complex dinner party seating arrangement: maximize guest interest while preventing conflicts. Efficiently solving this NP-complete problem for large datasets is computationally infeasible. GIST employs a carefully designed bicriteria greedy algorithm to approximate the solution efficiently. It iterates through potential distance thresholds, solves each corresponding independent set problem, and selects the best outcome. For any minimum distance d in the optimal solution, GIST guarantees comparable utility at a distance threshold of d/2. This systematic algorithm acts as a precise tuning knob, analyzing data distances to create spacing rules. It greedily selects the most valuable points that adhere to these rules, finding the optimal balance between information richness and data spread.
Empirical Results and Provable Guarantees
Strong Theoretical Guarantees
GIST provides the first algorithm with a strong, provable guarantee for the diversity-utility tradeoff in data selection. It guarantees a data subset value of at least half the absolute optimal solution (see paper). This robust guarantee offers practitioners a critical mathematical safety net, ensuring efficient trade-offs between utility maximization and diversification. Furthermore, we demonstrate the NP-hardness of achieving a subset value exceeding 0.56 of the optimal.
Tangible Real-World Impact
We rigorously evaluated GIST against state-of-the-art benchmarks across various ML applications where both diversity and utility are paramount:
- Random: A straightforward method promoting diversity and yielding good solutions.
- Margin: Selects data points where the model exhibits uncertainty, without inherent diversity incentives.
- k-center: Chooses a subset to minimize the maximum distance from any data point to its nearest selected representative, focusing on coverage.
- Submod: Selects important points (utility) while ensuring they are not too similar (diversity), though its diversity definition can falter with large datasets.
We also integrated GIST with other strategies to enhance their performance:
- GIST-margin: Applies GIST's strict diversity rules to the "hard case" selection strategy, preventing redundant picks of challenging examples.
- GIST-submod: Leverages the GIST framework for more rigorous diversity handling than the original submod approach.
Data Sampling for Image Classification
Experiments using a ResNet-56 model on datasets like ImageNet reveal GIST's significant advantages in single-shot subset selection. This efficient process reduces dataset volume in one step, preserving critical information—ideal for decreasing computational burdens or optimizing rendering. Unlike multi-stage methods, single-shot selection maximizes speed. GIST consistently yielded subsets that led to higher model accuracy than previous methods, demonstrating superior balance between coverage and non-redundancy.
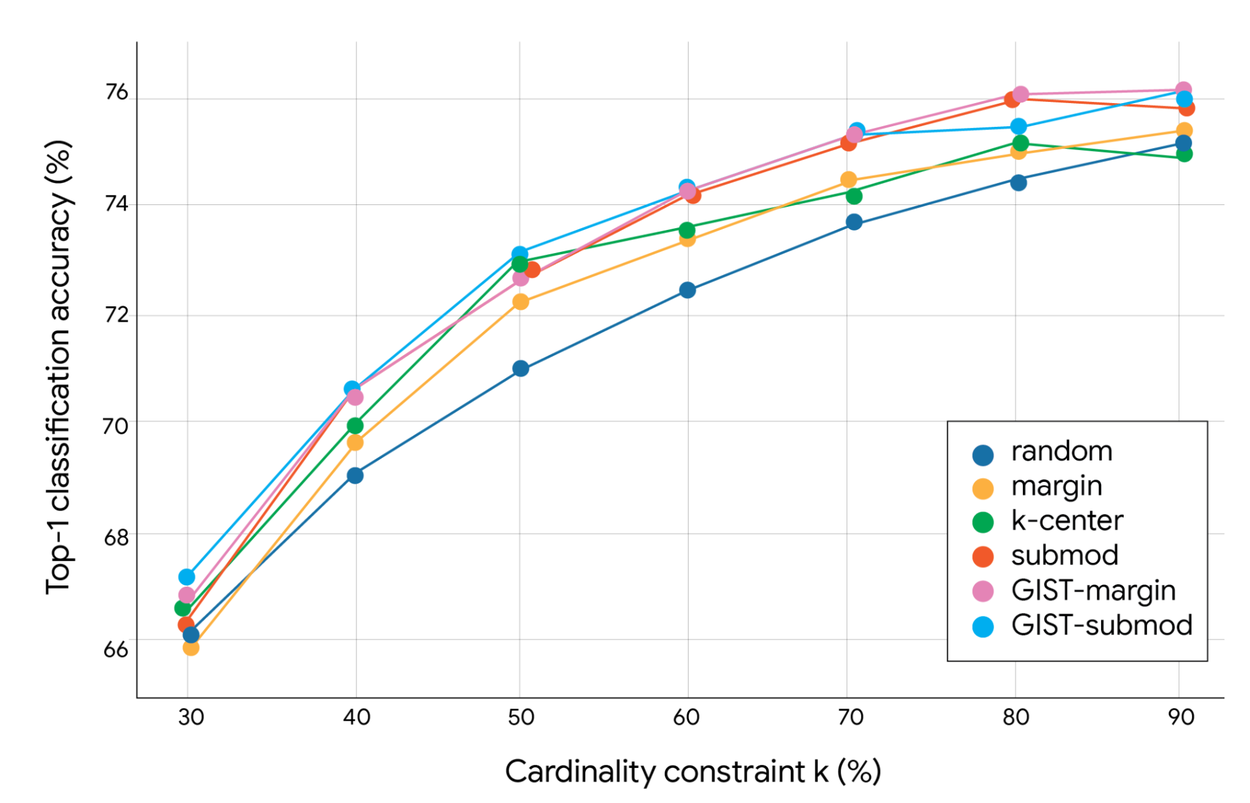
Top-1 classification accuracy (%) of GIST on ImageNet with varying single-shot data downsampling algorithms. The cardinality constraint strictly limits the number of items selected (e.g., 10% of 1.3 million images means a maximum of 130,000 images).
This capability is crucial for data-intensive tasks demanding the selection of the most informative and diverse images in a single step before computationally expensive model training commences. GIST’s superior subset selection consistently boosted model accuracy, confirming its enhanced ability to balance coverage and non-redundancy.
Exceptional Running Time
Despite the inherent complexity of the underlying problem, GIST's subset selection phase executes remarkably fast, with its running time often becoming negligible compared to the hours or days required for ML model training. This speed makes GIST highly practical for large-scale training pipelines involving billions of data points. The YouTube Home ranking team also recognized the value of the max-min diversity principle, employing a similar approach to enhance video recommendation diversity and improve long-term user value.
Conclusion: Powering Scalable AI Systems
Combining competing optimization goals—like maximizing utility while ensuring maximum diversity—has long been a significant hurdle in computational science. The GIST algorithm provides an efficient, single framework that effectively resolves this fundamental data selection trade-off. By decomposing the complex diversity–utility problem into a series of simpler, approximable tasks, GIST offers the ML community a provably effective tool. This research establishes a robust foundation for the next generation of scalable AI systems, ensuring that as data volumes explode, we can still train models using subsets that are both maximally informative and minimally redundant. GIST intelligently samples your data.
Acknowledgments
We extend our gratitude to Sara Ahmadian (Google Research); Srikumar Ramalingam, Giulia DeSalvo, and Gui Citovsky (Google DeepMind); and Cheenar Banerjee, Cristos Goodrow, Fabio Soldo, and Su-Lin Wu (YouTube) for their invaluable contributions. Matthew Fahrbach, Morteza Zadimoghaddam, and Srikumar Ramalingam contributed equally to this research project.