



Girish Narayanswamy and Maxwell A. Xu, Student Researchers, Google Research
Introducing LSM-2, powered by Adaptive and Inherited Masking (AIM), a pioneering self-supervised learning methodology designed to effectively process incomplete wearable sensor data. This innovative approach achieves superior performance across classification, regression, and generative tasks, eliminating the need for explicit data imputation.
Wearable technology transforms health monitoring by capturing continuous, multimodal physiological and behavioral data, including cardiac signals, sleep dynamics, activity metrics, and stress indicators. While advanced sensors generate vast datasets, the expense of labeling data remains substantial, necessitating real-time user input or complex clinical studies. Self-supervised learning (SSL) circumvents this challenge by leveraging unlabeled data to discern underlying patterns, such as subtle physiological interdependencies. Scaled effectively, SSL facilitates the development of robust foundation models capable of generating rich, generalizable representations vital for a broad spectrum of downstream health applications.
A critical limitation emerges when applying SSL to wearable data: current state-of-the-art methods presuppose complete, unbroken data streams. Real-world wearable sensor outputs are inherently fragmented, featuring gaps from device removal, charging periods, loose fittings, motion artifacts, power-saving modes, or environmental interference—phenomena we term "missingness." Our analysis of 1.6 million day-long windows revealed that not a single sample was entirely free of missing data. Historically, addressing this fragmentation has involved either statistical imputation to fill gaps or aggressive data filtering to discard incomplete instances. Neither approach is ideal; imputation can introduce biases, while filtering discards valuable information.
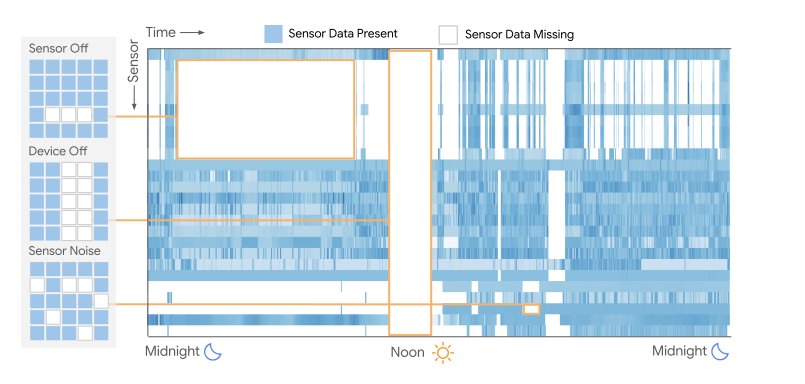
Missing data is ubiquitous in wearable sensor recordings. Common modes of missingness are highlighted above in a day-long sample of multimodal wearable sensor data. We note that no samples amongst our 1.6 million day-long windows have 0% missingness.
In our paper, “LSM-2: Learning from Incomplete Wearable Sensor Data”, we introduce Adaptive and Inherited Masking (AIM), a novel SSL training framework that directly processes incomplete data. Instead of treating data gaps as errors requiring imputation, AIM learns from fragmented recordings by accepting missingness as an inherent characteristic of real-world sensor data. Utilizing AIM, we developed the Large Sensor Model (LSM-2), a significant enhancement over our prior wearable sensor foundation model (LSM-1, presented at ICLR ‘25). LSM-2 demonstrates superior performance even with sensor failures or removed temporal segments, exhibiting substantially less performance degradation compared to models trained on imputed data.
Taking AIM with adaptive inherited masking
AIM's core innovation lies in its unique methodology for handling the inherent data gaps in real-world sensor streams. Unlike conventional SSL approaches that either discard incomplete data or attempt to fill missing values, AIM embraces these gaps as natural components of wearable data. Extending the masked autoencoder (MAE) pre-training framework, AIM learns the underlying data structure by reconstructing masked input samples.
However, while standard MAE methods employ a fixed masking ratio for efficient token dropout (reducing encoder computation by omitting a fixed number of masked tokens), sensor data fragmentation is unpredictable, leading to a variable number of masked tokens. AIM resolves this fundamental wearable data challenge by integrating token dropout with attention masking. During pre-training, the set of tokens to be masked includes those naturally present in the wearable sensor data plus those artificially masked for the reconstruction objective.
AIM initially applies dropout to a predetermined quantity of masked tokens, enhancing pre-training computational efficiency by shortening the sequence processed by the encoder. Subsequently, AIM adaptively manages any remaining masked tokens—whether naturally absent or part of the reconstruction task—through attention masking within the encoder's transformer block. For discriminative task fine-tuning and evaluation, where masked tokens exclusively represent naturally occurring data gaps, AIM utilizes attention masking for all masked tokens. This dual masking strategy, treating naturally occurring and artificially masked tokens equivalently, empowers AIM to effectively process the variable fragmentation intrinsic to wearable sensors.

AIM pre-training (A) and evaluation (B) for LSM-2. During pre-training, AIM uses the artificial mask to learn reconstruction and the inherited mask to model real-world missingness. Then, during evaluation, we can use the missingness-aware embedding to predict health targets, such as hypertension, directly from the inherently fragmented sensor data.
Training and evaluation
We utilized a comprehensive dataset comprising 40 million hours of wearable data from over 60,000 participants recorded between March and May 2024. This dataset was rigorously anonymized or de-identified to safeguard participant privacy. Participants wore various Fitbit and Google Pixel smartwatches and trackers, providing informed consent for their data to be used in research and the development of new health and wellness products and services. Demographic data—sex, age, and weight—were self-reported by participants.
For LSM-2 pre-training, we employed the AIM SSL technique. AIM implements a masked reconstruction training objective, enabling it to comprehend naturally missing data and impute artificially masked segments. This unified framework allows LSM-2 to accurately model the underlying structure, including missingness, inherent in wearable sensor data.
We established a suite of downstream tasks to rigorously evaluate the pre-trained model, utilizing metadata collected concurrently with sensor signals for research and development purposes. These tasks included user-annotated activities across 20 distinct categories (e.g., running, skiing, kayaking, golf) and self-reported diagnoses of hypertension and anxiety. This data was partitioned into fine-tuning and evaluation sets, ensuring that data from individual participants appeared exclusively in either the tuning or evaluation set, never both. Furthermore, data from individuals involved in the pre-training phase was excluded from fine-tuning and evaluation stages.
The generative capabilities of LSM-2 are assessed through tasks such as random imputation, temporal interpolation, temporal extrapolation (forecasting), and sensor imputation, as detailed in our prior work on LSM-1.
The utility of LSM-2 embeddings is evaluated using linear probing across multiple discriminative tasks. Specifically, we measure the applicability of LSM-2 embeddings to binary hypertension classification, binary anxiety classification, and 20-class activity recognition. We also assess LSM-2’s capacity for modeling physiology through age and BMI regression tasks.
Key results
The AIM-enhanced LSM-2 model demonstrates exceptional versatility, surpassing its predecessor, LSM-1, in three pivotal domains: health condition and activity classification (including hypertension, anxiety, and 20-class activity recognition), missing data reconstruction (such as restoring absent sensor signals), and predicting continuous health metrics (like BMI, with enhanced correlation). Comprehensive comparative analyses against supervised and pre-trained baselines are available in our research paper.
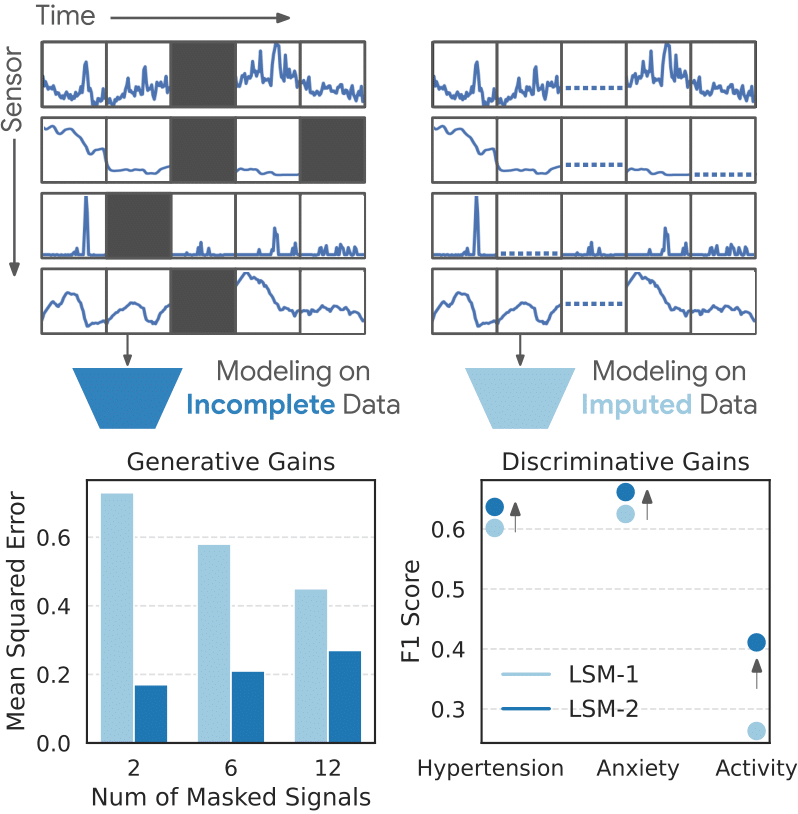
LSM-2 models real-world missingness without imputation, allowing it to achieve lower reconstruction error (left) and higher classification scores (right) as compared to LSM-1.
LSM-2 excels in realistic scenarios where sensors may fail or data is incomplete. The figure below simulates situations involving the complete loss of sensor feeds or entire daily data segments. This accurately reflects the reality of varying wearable sensor configurations and intermittent device usage. In these simulated conditions, the AIM-based LSM-2 proves significantly more resilient to data ablations than LSM-1.
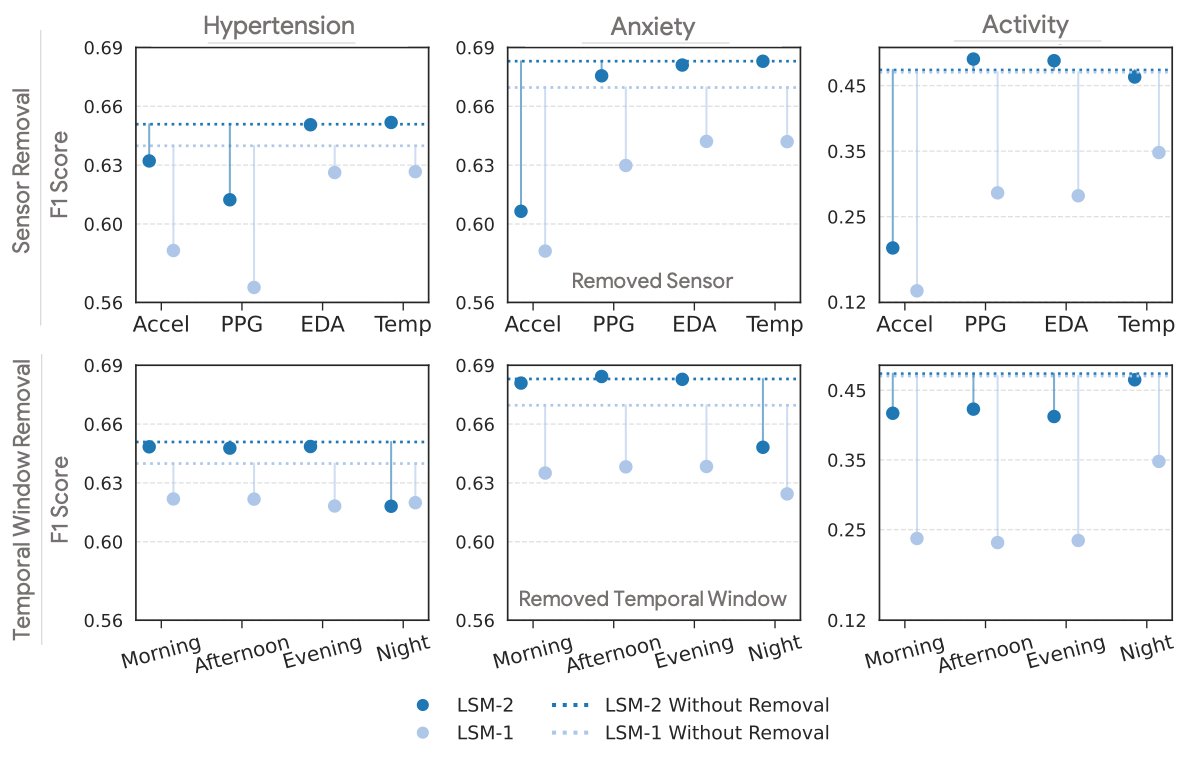
LSM-2 is more robust to missing data than LSM-1, degrading less from its original performance (dotted line) than its predecessor when whole sensor feeds or periods of the day are ablated.
Furthermore, LSM-2 demonstrates superior scaling across users, data volume, computational resources, and model size compared to LSM-1. While LSM-1 exhibits signs of performance plateauing, LSM-2 continues to improve with increased data and has yet to reach its saturation point.
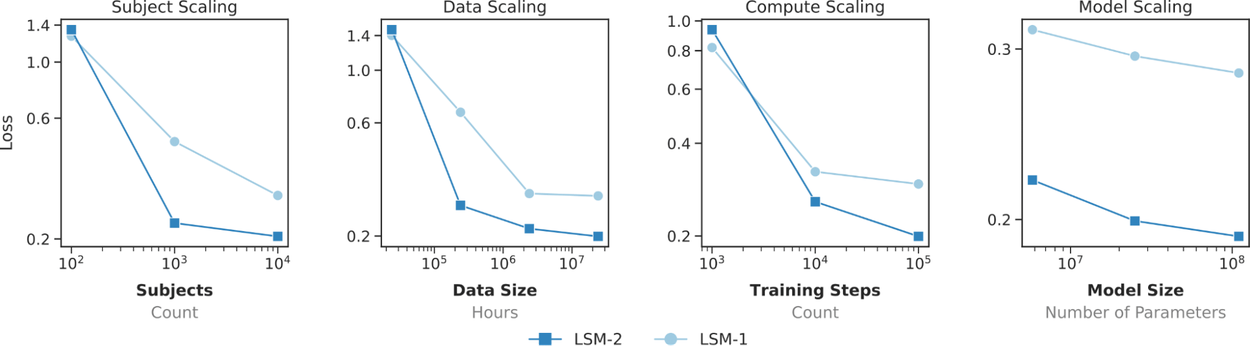
LSM-2 exhibits improved scaling over LSM-1 across subjects, data, compute, and model size.
Conclusion
The LSM-2 foundation model, pre-trained with AIM, signifies a substantial advancement towards more intelligent and practical wearable health technologies. Fundamentally, AIM empowers LSM-2 to comprehend and exploit the natural data gaps in real-world sensor streams, thereby deriving reliable insights from imperfect information. This innovation enables wearable AI to finally embrace the inherent complexities of sensor data, preserving data integrity while maximizing the utilization of all available information.
Acknowledgements
This research is a collaborative effort involving Google Research, Google Health, Google DeepMind, and partner teams. The following researchers significantly contributed to this work: Maxwell A. Xu, Girish Narayanswamy, Kumar Ayush, Dimitris Spathis, Shun Liao, Shyam Tailor, Ahmed Metwally, A. Ali Heydari, Yuwei Zhang, Jake Garrison, Samy Abdel-Ghaffar, Xuhai Xu, Ken Gu, Jacob Sunshine, Ming-Zher Poh, Yun Liu, Tim Althoff, Shrikanth Narayanan, Pushmeet Kohli, Mark Malhotra, Shwetak Patel, Yuzhe Yang, James M. Rehg, Xin Liu, and Daniel McDuff. We also extend our gratitude to the participants who generously contributed their data for this study.