


Discover a robust, production-grade framework designed to rigorously test and quantify the real-world performance of advanced agentic AI systems. This authoritative guide empowers you to master agent evaluation, moving beyond basic language model metrics. We dissect the critical differences in assessing agents versus standalone LLMs, present the four essential pillars of agent performance evaluation, and detail pragmatic metrics for each. Learn to construct automated, human-powered, or hybrid evaluation pipelines engineered to proactively identify and rectify failures before they impact users. Let's dive into optimizing your AI agents for unparalleled effectiveness.
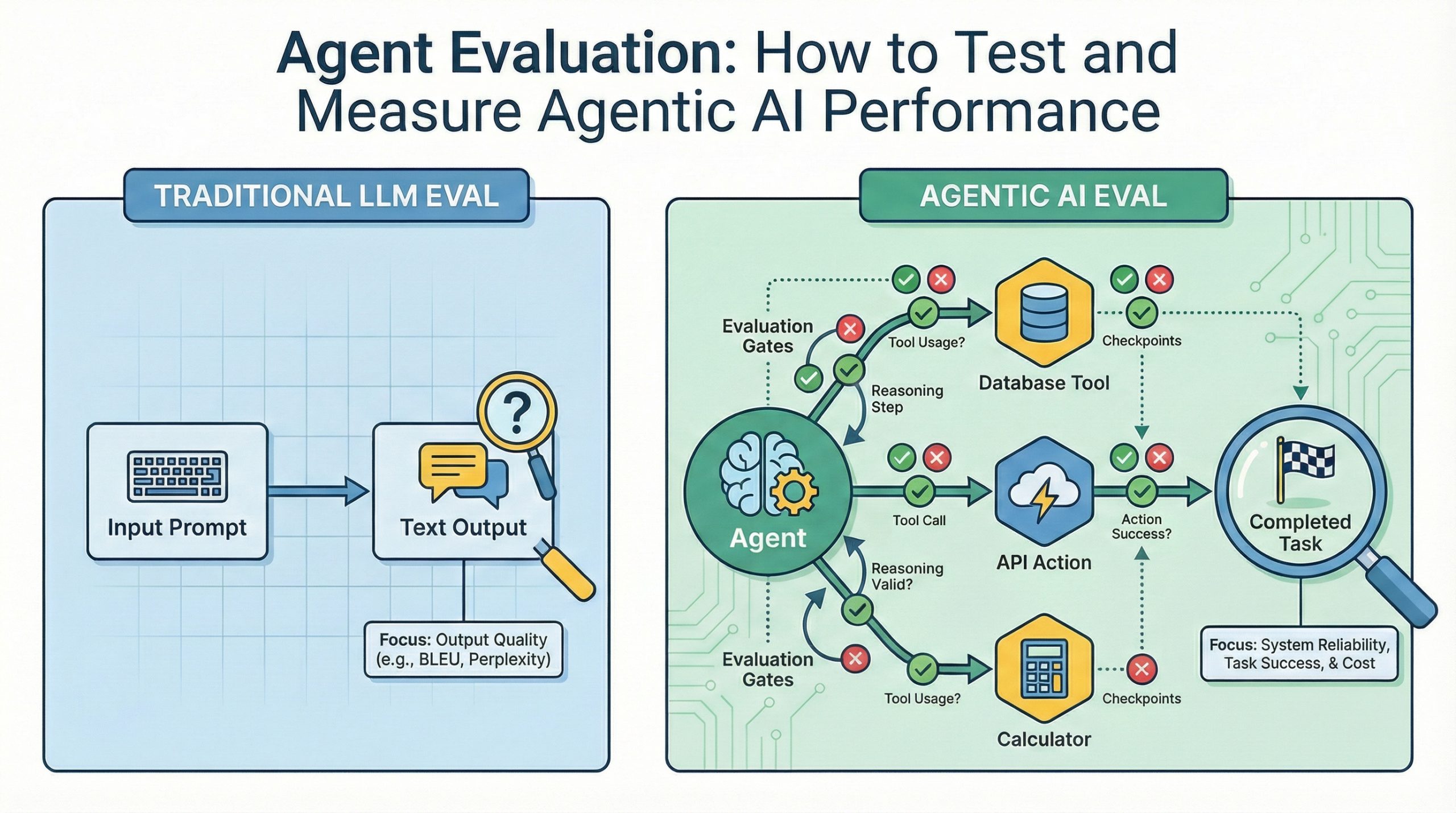
Agent Evaluation: How to Test and Measure Agentic AI Performance (click to enlarge)
Image by Author
Revolutionize Agentic AI Evaluation
Modern AI agents, adept at tool utilization, autonomous decision-making, and multi-stage task execution, are no longer experimental concepts. The paramount challenge lies in guaranteeing their consistent and reliable operation within production environments. Conventional language model evaluation metrics, such as BLEU scores or perplexity, are fundamentally inadequate for agents. Key questions arise: Did the agent flawlessly accomplish its objective? Were tools deployed with optimal precision? Could the agent gracefully recover from operational setbacks? This comprehensive guide unveils a practical framework for evaluating agent performance across four critical dimensions essential for production readiness. You will gain profound insights into what metrics are indispensable, which evaluation methodologies align with diverse operational needs, and how to engineer an evaluation pipeline that preemptively detects anomalies before they reach end-users.
Distinguishing Agent Performance Evaluation from LLM Assessment
Evaluating standalone language models primarily focuses on textual output quality, encompassing metrics like coherence, factual veracity, and response pertinence. These benchmarks operate under the assumption that the model's function concludes with text generation. However, agent evaluation demands a paradigm shift. Agents transcend mere text generation; they actively execute actions, invoke specialized tools with precise parameters, orchestrate sequential decisions building upon prior states, and must possess resilience against external API failures or unexpected data inputs. Consider a customer support agent: it must retrieve order statuses, initiate refunds, and update customer records. Standard LLM metrics offer zero insight into whether the correct API endpoints were invoked, if accurate customer identifiers were transmitted, or how exceptions like refund requests exceeding policy thresholds were managed. Agent evaluation must rigorously assess task completion efficacy, tool invocation accuracy, multi-stage workflow reasoning integrity, and robust failure remediation capabilities. Comparing language model evaluation to agent evaluation is akin to contrasting a calculator's display veracity with the comprehensive validation of an entire financial system – one focuses on superficial output quality, while the other scrutinizes the system's ability to fulfill its intended purpose reliably under real-world operational pressures.
The Quintessential Four Pillars of Agent Evaluation
A sophisticated agent evaluation framework meticulously assesses four interconnected dimensions, each designed to address distinct failure modes that can compromise agent reliability in production. Task Success verifies the agent's objective attainment. This necessitates precise definition: for a customer service agent, "resolved the customer inquiry" could signify a successfully answered question (outcome-centric), completion of all requisite workflow stages (process-centric), or expressed customer contentment (quality-centric). Divergent definitions dictate varied evaluation methodologies and optimization strategies. Tool Usage Quality scrutinizes the appropriateness, correctness, and timing of tool invocations. Suboptimal tool usage manifests as: invoking irrelevant tools (relevance failures), supplying malformed parameters leading to API errors (accuracy failures), executing redundant calls that inflate token consumption and latency (efficiency failures), or omitting critical tool calls (completeness failures). Robust tool-invocation patterns are definitive in differentiating production-ready agents from mere demonstrations. Reasoning Coherence evaluates the logical soundness and justification of the agent's decision-making trajectory given available information. Production systems mandate interpretability and debuggability. An agent that achieves a correct outcome through fallacious reasoning is prone to unpredictable failures as environmental conditions fluctuate. Reasoning evaluation confirms that intermediate steps logically derive from prior observations, that alternative solutions were considered, and that beliefs were appropriately updated upon encountering contradictory information. Finally, Cost-Performance Trade-offs quantify the resources consumed per successful task (tokens, API calls, latency, infrastructure) against the value generated. An agent achieving 95% task success but consuming 50 API calls and 30 seconds per interaction may be technically accurate but economically unsustainable. Evaluation must strike a crucial balance between accuracy and operational expenses to identify architectures that deliver acceptable performance at a viable cost. This evaluation rubric provides concrete measurement dimensions:
| Pillar | What You’re Measuring | How to Measure | Example Metric |
|---|---|---|---|
| Task Success | Did the agent complete the objective? | Binary outcome plus quality scoring | Task completion rate (0-100%) |
| Tool Usage Quality | Did it call the right tools with correct arguments? | Deterministic validation plus LLM-as-a-Judge | Tool call accuracy, parameter correctness |
| Reasoning Coherence | Were intermediate steps logical and justified? | LLM-as-a-Judge with chain-of-thought analysis | Reasoning quality score (1-5 scale) |
| Cost-Performance | What did it cost versus value delivered? | Token tracking, API monitoring, latency measurement | Cost per successful task, time to completion |
Three Strategic Evaluation Approaches: Automated, Human, and Hybrid
Agent evaluation implementations broadly fall into three categories, distinguished by the entity performing the assessment: LLM-as-a-Judge leverages a more sophisticated model to autonomously appraise your agent's outputs. Advanced models like GPT-4 or Claude can ascertain whether your agent's responses meet quality benchmarks that are prohibitively complex for deterministic rule definition. The evaluator model receives the agent's input, output, and a grading rubric, subsequently assigning scores across dimensions such as helpfulness, accuracy, or policy adherence. This method adeptly handles subjective criteria like tonal appropriateness or explanatory clarity, which resist simple validation, while preserving the velocity and consistency of automated testing. LLM-as-a-Judge excels when explicit evaluation criteria can be articulated in the prompt and the evaluator possesses sufficient cognitive capacity for the desired assessment dimensions. Vigilance is required against potential biases such as leniency (grade inflation), excessive strictness (false negatives), or inter-case inconsistency (scoring instability). Human evaluation engages actual individuals to scrutinize agent outputs against defined quality standards. This approach is invaluable for uncovering edge cases and subjective quality nuances that automated methods might overlook, particularly in domains demanding specialized expertise, cultural sensitivity, or intricate judgment. The primary challenges are inherent in cost, temporal investment, and scalability. Human evaluation can range from $10 to $50 per task, depending on complexity and reviewer expertise, requires hours to days for completion, and cannot provide continuous monitoring of production traffic. Human evaluation is optimally employed for calibrating datasets, in-depth failure analysis, and periodic quality audits, rather than continuous surveillance. Hybrid approaches integrate automated filtering with judicious human review for pivotal instances. Initiate with LLM-as-a-Judge for an initial evaluation of all agent outputs, subsequently directing identified failures, edge cases, and high-stakes decisions to human experts for detailed examination. This strategy synergizes the speed and broad coverage of automation with essential human oversight for critical junctures. This methodology mirrors evaluation strategies prevalent in RAG systems, where automated metrics identify obvious defects, while human review validates retrieval relevance and answer precision. The selection of an evaluation method is contingent upon your specific operational constraints. High-volume, low-consequence tasks are ideally suited for pure automation. High-stakes decisions necessitating nuanced quality assessments demand human intervention. Most production systems realize significant benefits from hybrid approaches that skillfully balance automated efficiencies with targeted human oversight.
Pioneering Agent-Specific Benchmarks and Evaluation Tools
The burgeoning agent evaluation landscape features specialized benchmarks engineered to assess capabilities extending beyond rudimentary text generation. AgentBench offers multi-domain testing across web navigation, database interrogation, and knowledge retrieval tasks. WebArena concentrates on web-centric agents requiring site navigation, form completion, and multi-page workflow execution. GAIA evaluates general intelligence through complex tasks demanding multi-step reasoning and tool utilization. ToolBench rigorously assesses tool invocation accuracy across thousands of real-world API scenarios. These benchmarks establish crucial baseline performance expectations. Understanding that current leading agents achieve 45% success on GAIA's most challenging tasks provides a vital reference point for evaluating whether your 35% success rate signifies a critical architectural issue or simply reflects inherent task difficulty. Benchmarks also facilitate direct comparative analysis when evaluating disparate agent frameworks or foundational models pertinent to your specific use case. Implementation tools are increasingly available to streamline evaluation within production systems. LangSmith provides integrated agent tracing, visualizing tool calls, intermediate reasoning steps, and decision points, complemented by built-in evaluation pipelines that execute automatically with every agent invocation. Langfuse delivers open-source observability coupled with customizable evaluation metric support, empowering you to define domain-specific grading criteria beyond standard benchmarks. Frameworks initially developed for RAG evaluation, such as RAGAS, are undergoing extensions to accommodate agent-specific metrics, including tool call precision and multi-stage reasoning coherence. You are not required to construct evaluation infrastructure from foundational principles. Select tools based on your preference for hosted solutions offering rapid deployment (LangSmith), complete customization capabilities (Langfuse), or seamless integration with existing RAG workflows (RAGAS extensions). The chosen evaluation methodology holds greater significance than the specific tool employed, provided your selected platform robustly supports the automated, human, or hybrid approach necessitated by your application's demands.
Constructing Your Advanced Agent Evaluation Pipeline
The cornerstone of effective evaluation pipelines is a foundational element often overlooked: the golden dataset. This meticulously curated collection, comprising 20-50 exemplar cases, showcases ideal inputs and their corresponding expected outputs for your agent. Each example precisely delineates the task, the definitive correct solution, the requisite tools for invocation, and the logical reasoning process. This ground truth serves as the indispensable benchmark against which all performance is measured. Developing a golden dataset necessitates substantial engineering effort. Diligently review your production logs to identify representative tasks spanning a spectrum of complexities. For each task, manually validate the correctness of the solution and meticulously document the rationale for why alternative approaches would prove suboptimal. Incorporate edge cases that have historically precipitated agent failures during testing. Continuously update the dataset as new failure modes are identified. This meticulous preparatory work profoundly influences all subsequent evaluation stages. 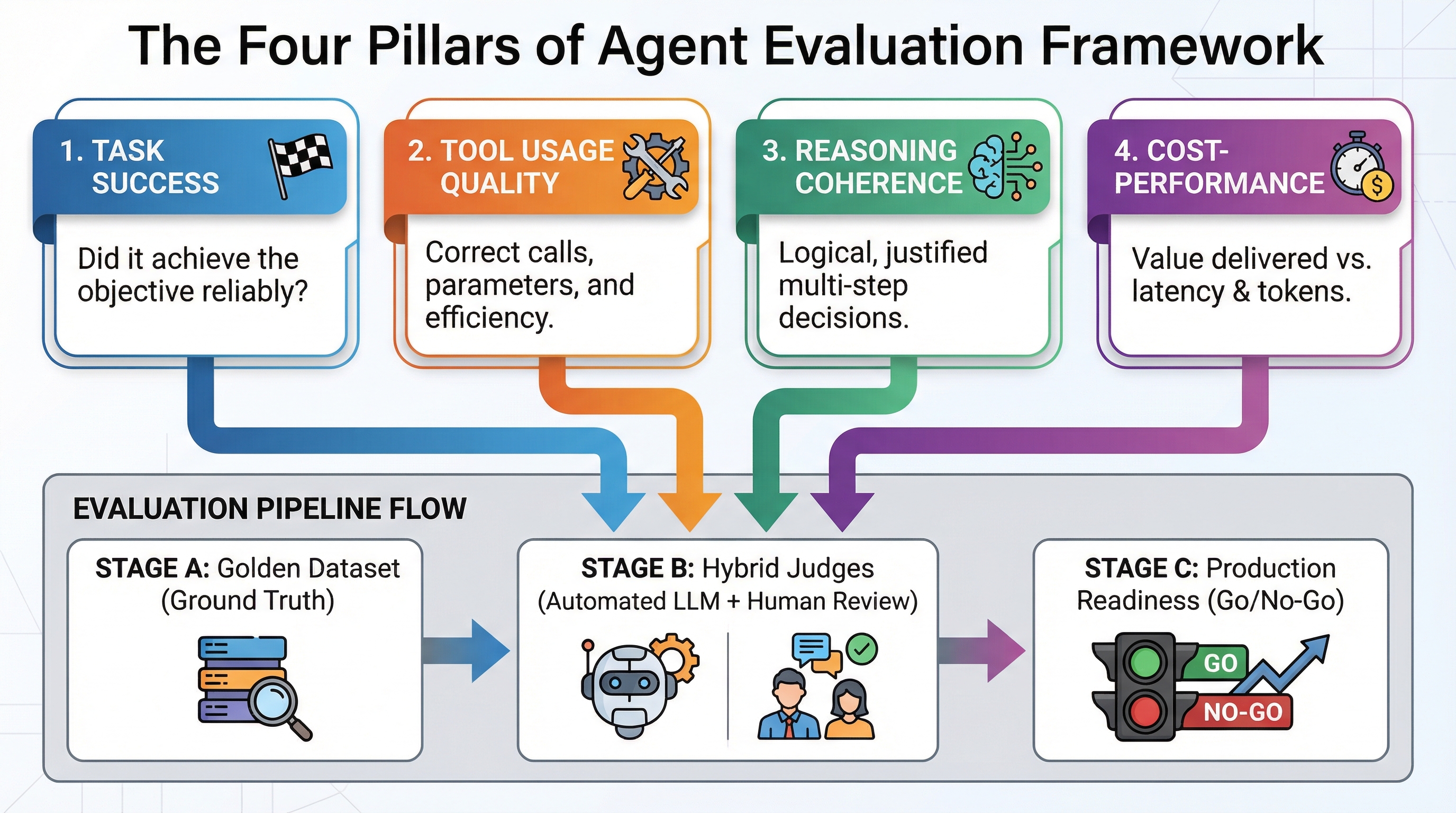 Define unambiguous success criteria that align harmoniously with your four core pillars. Regarding task success, stipulate whether partial completion is acceptable or if only complete resolution constitutes success. For tool usage, determine if invoking redundant tools that do not negatively impact the outcome should be classified as a failure. For reasoning, decide whether the elegance of the solution or merely its correctness is the paramount concern. For cost-performance, establish stringent thresholds for acceptable latency and token consumption. Ambiguous criteria invariably lead to evaluation systems that fail to capture meaningful insights. Select three to five core metrics that comprehensively span your four pillars. Task completion rate directly addresses task success. Tool call accuracy pertains to usage quality. An LLM-as-a-Judge reasoning score evaluates coherence. Average tokens per task quantifies cost-performance. These select metrics provide robust coverage without overwhelming monitoring dashboards. Implement automated LLM-as-a-Judge evaluation that executes prior to every production deployment. This proactive measure effectively identifies obvious regressions, such as tool calls with mismatched parameters or reasoning trajectories that contradict the task objective. Automated evaluation should strategically block deployments exhibiting metric degradation exceeding predefined thresholds—typically a 5-10% decline in success rates or a 20-30% escalation in cost per task. Establish rigorous human review protocols for identified failures and edge cases. When automated evaluation flags an anomaly, route it to domain experts to ascertain whether the evaluation itself was accurate or if it exposed an underlying evaluation bug. When agents encounter scenarios absent from your golden dataset, task human reviewers with assessing response quality and validating new examples to augment your ground truth. This iterative refinement cycle mirrors the established best practices observed in RAG systems, where continuous evaluation and dataset expansion are instrumental in driving reliability enhancements. Commence with a simplified approach and progressively introduce sophistication as your understanding of failure patterns deepens. Initiate with task success rates measured against your golden dataset. Once completion metrics are reliably tracked, integrate tool usage metrics. Subsequently, introduce reasoning evaluation. Finally, optimize cost-performance metrics once quality indicators have stabilized. Attempting to implement comprehensive evaluation from the outset can introduce unnecessary complexity, obscuring whether your agent is fundamentally functional.
Define unambiguous success criteria that align harmoniously with your four core pillars. Regarding task success, stipulate whether partial completion is acceptable or if only complete resolution constitutes success. For tool usage, determine if invoking redundant tools that do not negatively impact the outcome should be classified as a failure. For reasoning, decide whether the elegance of the solution or merely its correctness is the paramount concern. For cost-performance, establish stringent thresholds for acceptable latency and token consumption. Ambiguous criteria invariably lead to evaluation systems that fail to capture meaningful insights. Select three to five core metrics that comprehensively span your four pillars. Task completion rate directly addresses task success. Tool call accuracy pertains to usage quality. An LLM-as-a-Judge reasoning score evaluates coherence. Average tokens per task quantifies cost-performance. These select metrics provide robust coverage without overwhelming monitoring dashboards. Implement automated LLM-as-a-Judge evaluation that executes prior to every production deployment. This proactive measure effectively identifies obvious regressions, such as tool calls with mismatched parameters or reasoning trajectories that contradict the task objective. Automated evaluation should strategically block deployments exhibiting metric degradation exceeding predefined thresholds—typically a 5-10% decline in success rates or a 20-30% escalation in cost per task. Establish rigorous human review protocols for identified failures and edge cases. When automated evaluation flags an anomaly, route it to domain experts to ascertain whether the evaluation itself was accurate or if it exposed an underlying evaluation bug. When agents encounter scenarios absent from your golden dataset, task human reviewers with assessing response quality and validating new examples to augment your ground truth. This iterative refinement cycle mirrors the established best practices observed in RAG systems, where continuous evaluation and dataset expansion are instrumental in driving reliability enhancements. Commence with a simplified approach and progressively introduce sophistication as your understanding of failure patterns deepens. Initiate with task success rates measured against your golden dataset. Once completion metrics are reliably tracked, integrate tool usage metrics. Subsequently, introduce reasoning evaluation. Finally, optimize cost-performance metrics once quality indicators have stabilized. Attempting to implement comprehensive evaluation from the outset can introduce unnecessary complexity, obscuring whether your agent is fundamentally functional.
Navigating Common Agent Evaluation Pitfalls
Three prevalent failure modes consistently undermine agent evaluation initiatives. Firstly, many teams conduct evaluations using synthetic data that inadequately represents real-world production complexity. Agents that perform flawlessly on pristine test cases frequently falter when end-users submit ambiguous instructions, reference prior conversational context, or combine multiple distinct requests. The solution lies in populating your golden dataset with actual production failures rather than relying on idealized scenarios. Secondly, evaluation criteria can drift away from core business objectives. Teams may prioritize metrics such as API call reduction or reasoning elegance that lack a direct correlation to actual business impact: was the customer's issue truly resolved? Continually validate that your evaluation metrics accurately predict real-world success by comparing agent performance scores against actual user satisfaction data or tangible business outcomes. Thirdly, evaluation systems fail to detect regressions due to insufficient test coverage across the agent's complete capability spectrum. An agent might excel at data retrieval tasks while silently failing on computational tasks, yet limited test examples only exercise the retrieval pathway. Effective test design demands inclusion of examples that encompass every design pattern your agent implements and each tool within its functional repertoire. These pitfalls share a common underlying cause: treating evaluation as a static, one-time setup task rather than a dynamic, ongoing practice. Achieving sustained evaluation reliability necessitates continuous investment in test case quality, metric validation, and coverage expansion commensurate with the evolving capabilities of your agent.
Conclusion
Ensuring robust agent evaluation demands a multifaceted approach, rigorously measuring task success, tool usage quality, reasoning coherence, and cost-performance trade-offs through a synergistic blend of automated LLM-as-a-Judge assessments, deterministic validation, and targeted human oversight. The indispensable foundation for this process is a meticulously curated golden dataset, comprising 20-50 examples that precisely define success parameters for your unique use case. Initiate your evaluation journey with straightforward task completion metrics applied to authentic production scenarios. Introduce advanced evaluation sophistication only after a thorough understanding of your prevalent failure modes has been achieved. Select your evaluation tools based on practical considerations such as hosted convenience versus the need for comprehensive customization, while recognizing that the strategic approach to evaluation fundamentally outweighs the specific platform utilized. For detailed implementation guidance on constructing production-ready evaluation pipelines, consult Anthropic's seminal work, “Demystifying evals for AI agents.” This resource provides an eight-step technical roadmap, complete with grader schemas, YAML configurations, and real-world customer case studies illustrating how leading organizations like Descript and Bolt have strategically evolved their evaluation methodologies.