


February 11, 2026 Manish Purohit, Research Scientist, Google Research We introduce advanced, demonstrably effective algorithms engineered for scheduling jobs without interruptions on dynamic cloud infrastructure where machine availability exhibits constant fluctuation.
Expedited Navigation
In the domain of sophisticated job scheduling algorithms, computing resources are frequently conceptualized as static entities: a server possesses a fixed number of CPUs, or a cluster maintains a constant pool of available machines. However, the practical reality of modern, large-scale cloud computing environments is significantly more fluid. Resources undergo constant flux, influenced by hardware failures, scheduled maintenance cycles, or power constraints. Crucially, within tiered scheduling systems, high-priority tasks frequently commandeer resources on demand, leaving a time-varying quantity of residual capacity for lower-priority batch jobs. Visualize a high-end restaurant where tables are perpetually reserved for VIPs at varied intervals; orchestrating the seating of regular patrons amidst these dynamic reservations presents a formidable scheduling challenge. When these lower-priority jobs are non-preemptive—meaning they cannot be paused and subsequently resumed—the consequences of interruption are severe. If a job is halted due to a capacity reduction, all its executed progress is irretrievably lost. The scheduler faces a critical decision: Should we initiate this lengthy job immediately, risking a future capacity deficit? Or should we defer its commencement until a more stable window presents itself, potentially jeopardizing its deadline? In our publication “Non-preemptive Throughput Maximization under Time-varying Capacity,” presented at SPAA 2025, we pioneer the investigation into optimizing throughput (encompassing total weight or the count of successfully completed jobs) within environments characterized by fluctuating available capacity. Our research delivers the inaugural constant-factor approximation algorithms for several variations of this intricate problem, providing a robust theoretical framework for constructing more resilient schedulers tailored for volatile cloud landscapes. These algorithms guarantee that the difference between the algorithm's outcome and the absolute optimal solution remains bounded by a fixed constant, irrespective of the problem's scale.
Precise Scheduling Problem Definition
Our investigation centers on formulating a scheduling model that meticulously incorporates a spectrum of essential constraints. We analyze a singular machine (or a coordinated cluster) operating under a capacity profile that dynamically changes over time. This profile dictates the maximum number of jobs that can be executed concurrently at any given moment. We are presented with a collection of prospective jobs, each precisely defined by four critical attributes: the time it becomes available for execution (release time), an inviolable time by which it must be completed (deadline), the requisite continuous execution duration (processing time), and the value accrued upon successful completion (weight).
- Release time: The precise moment a job becomes eligible for execution.
- Deadline: The absolute final time by which a job must be concluded.
- Processing time: The uninterrupted duration the machine requires to finalize the job.
- Weight: The quantifiable value achieved upon the successful completion of the job.
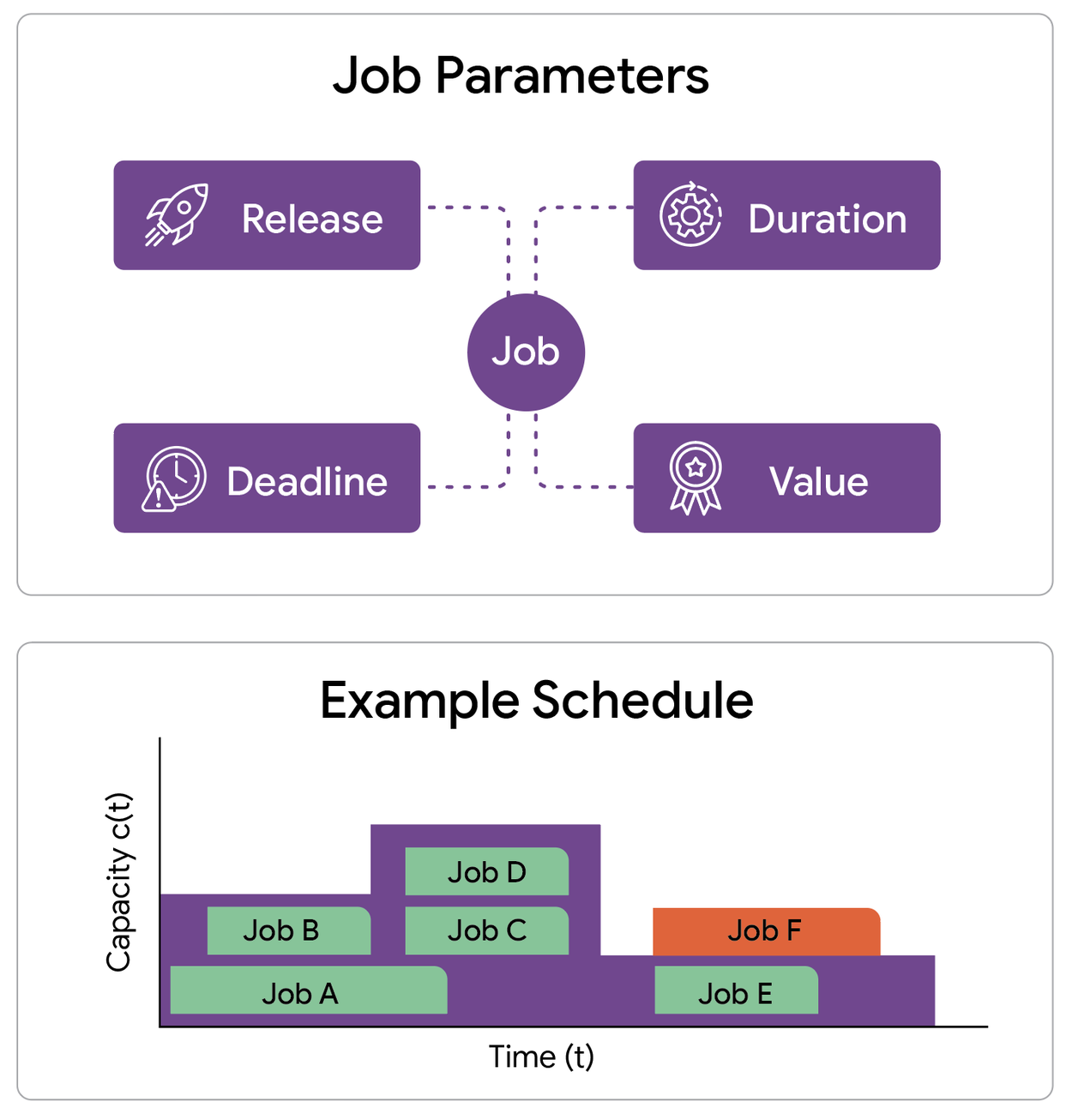
An illustrative instance of the throughput maximization problem involves a set of jobs, each possessing defined release times, deadlines, durations, and associated values, alongside a fluctuating capacity profile for the machine. This capacity profile governs the maximum number of jobs that can be processed concurrently at any given moment.
The paramount objective is to meticulously select a subset of these jobs and orchestrate their execution such that each chosen job runs continuously within its permissible time window. The critical constraint mandates that at any point in time, the aggregate number of actively running jobs must not exceed the prevailing resource capacity. Our aim is to achieve maximal throughput, defined as the cumulative weight of all successfully completed jobs. We tackle this complex problem across two distinct operational paradigms: offline, where all future job arrivals and capacity fluctuations are precisely known in advance; and online, where jobs materialize in real-time, compelling the scheduler to render irrevocable decisions without foreknowledge of subsequent arrivals. In the online scenario, the capacity landscape is still predetermined.
Key Findings: Offline Scheduling Scenarios
Within the offline scheduling context, where proactive planning is feasible, we observe that remarkably straightforward strategies yield highly effective outcomes. Given that determining the absolute optimal schedule in this domain is classified as NP-hard, our focus is directed towards algorithms that offer rigorous approximation guarantees. We meticulously analyze a simple, iterative strategy termed Greedy, which prioritizes scheduling the job poised for the earliest completion. We rigorously prove that this fundamental heuristic attains a 1/2-approximation ratio (a highly competitive performance benchmark) when jobs possess uniform profits. This implies that even under the most adverse conditions, with adversarially selected jobs and capacity profiles, our straightforward algorithm is guaranteed to successfully schedule at least half the number of jobs achievable by an optimal scheduler. This performance benchmark is commensurate with the guarantees afforded by the Greedy strategy on simpler, unit-capacity machines capable of processing only a single task at a time. When jobs exhibit varying profit margins, we employ a sophisticated primal-dual framework to achieve a 1/4-approximation ratio.
Key Findings: Online Scheduling Scenarios
The true complexity emerges within the online scheduling paradigm, characterized by the dynamic arrival of jobs and the imperative for the scheduler to execute immediate, irreversible decisions without insight into future job arrivals. We quantify the performance of an online algorithm through its competitive ratio, which represents the worst-case comparison between the throughput achieved by our online algorithm and that of an optimal algorithm possessing complete a priori knowledge of all jobs. Standard non-preemptive algorithms falter significantly in this setting, as their competitive ratios approach zero. This degradation occurs because a single ill-advised decision to schedule an extended job can irrevocably compromise the potential to complete numerous subsequent, shorter jobs. Consider, for instance, a scenario where each completed job contributes identical weight, irrespective of its duration; in such a case, completing multiple short jobs yields substantially greater profit than completing a single long job. To render the online problem tractable and accurately reflect real-world operational flexibility, we investigated two models that permit an active job to be interrupted if a more advantageous opportunity arises (though only jobs that are successfully restarted and subsequently completed non-preemptively are counted towards overall throughput).
Interruption Permitting Restarts
In this operational model, an online algorithm is expressly permitted to interrupt a job currently in execution. While any partial work invested in the interrupted job is forfeited, the job itself persists within the system and remains eligible for subsequent retries.
We have determined that the strategic flexibility afforded by permitting job restarts confers substantial advantages. A refined iteration of the Greedy algorithm, which consistently schedules the job projected for the earliest completion, continues to achieve a robust 1/2-competitive ratio, mirroring the performance observed in the offline scheduling context.
Interruption Precluding Restarts
Within this more stringent model, all progress made on an interrupted job is irrevocably lost, and the job itself is permanently discarded. Regrettably, our analysis reveals that under this exacting regime, any online algorithm is susceptible to encountering a sequence of jobs that compels decisions inherently detrimental to future work completion. Once again, the competitive ratios for all online algorithms gravitate towards zero. Our analysis of these particularly challenging instances has guided our focus towards the practical scenario where all jobs share a common, overarching deadline (e.g., all data processing operations must be finalized before the nightly batch execution). For these common-deadline job sets, we have devised novel algorithms that exhibit constant competitive ratios. Our algorithm is remarkably intuitive, and we detail its operation for a simplified unit capacity profile, enabling the scheduling of a single job at any given time.
In this specific context, our algorithm meticulously maintains a tentative schedule by assigning jobs that have already arrived to distinct, non-overlapping time intervals. Upon the arrival of a new job, the algorithm dynamically adjusts the tentative schedule by executing the first applicable action from the following four options:
1. Add the new job to the tentative schedule by allocating it an available time interval.
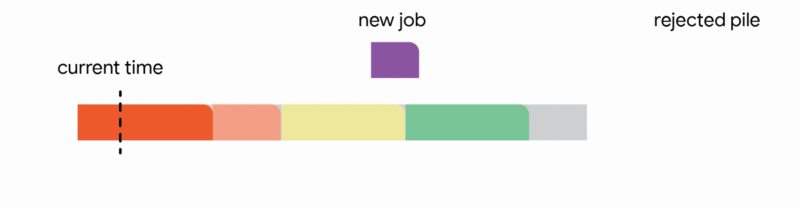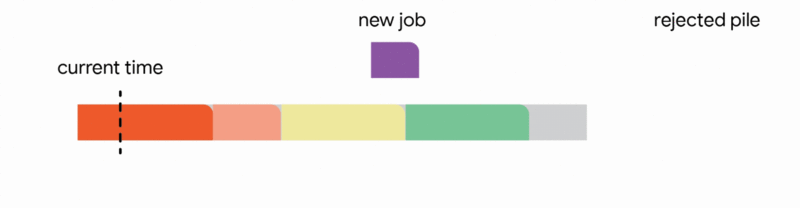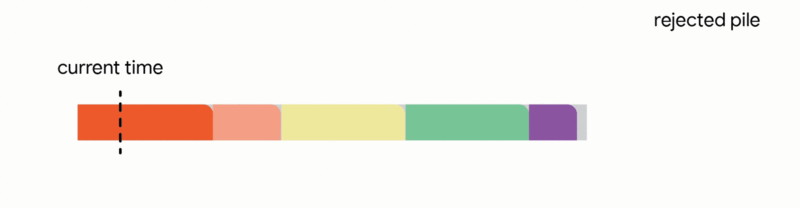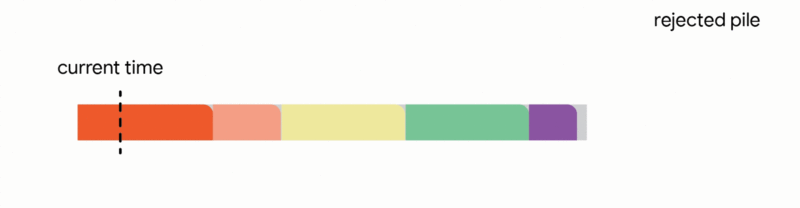
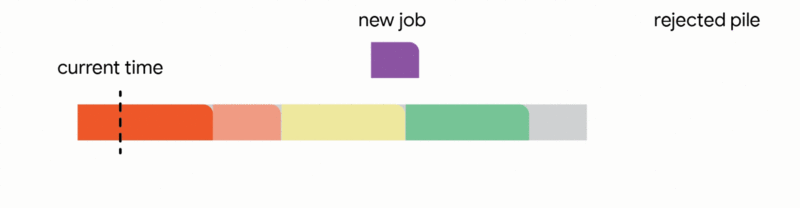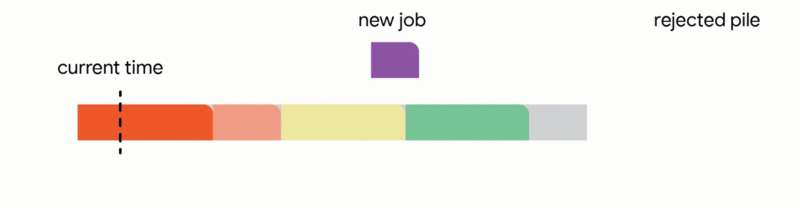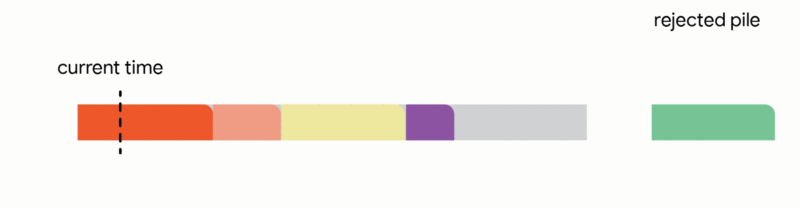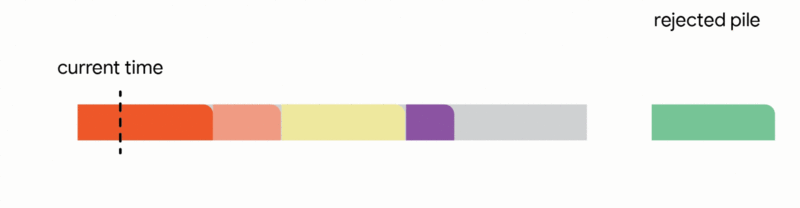
2. Replace a previously scheduled future job within the tentative schedule if the newly arrived job is substantially shorter.
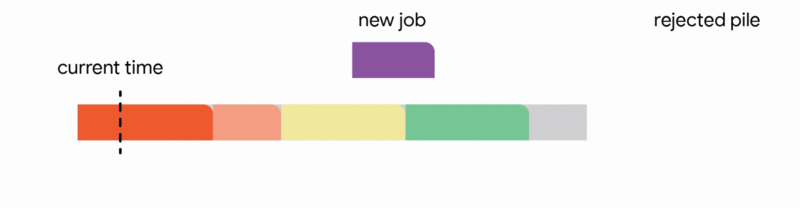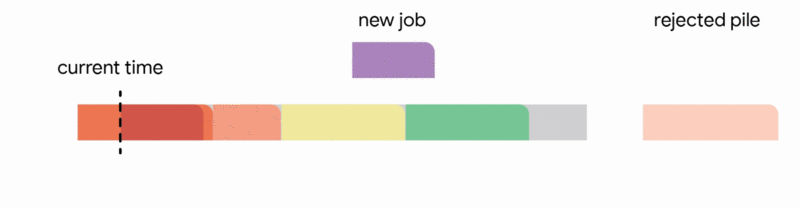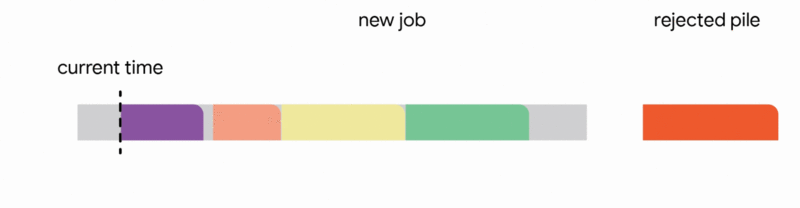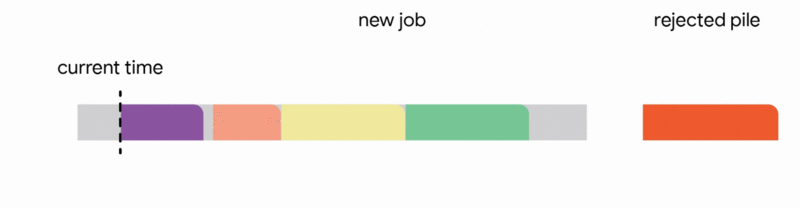
3. Interrupt the currently executing job if the new job's processing time is less than the remaining execution time of the active job.
4. Discard the newly arrived job entirely.
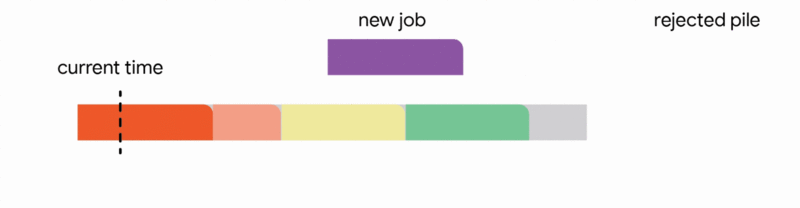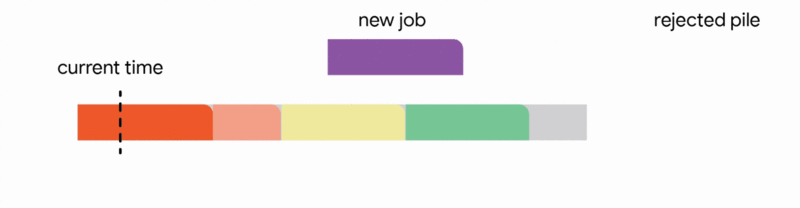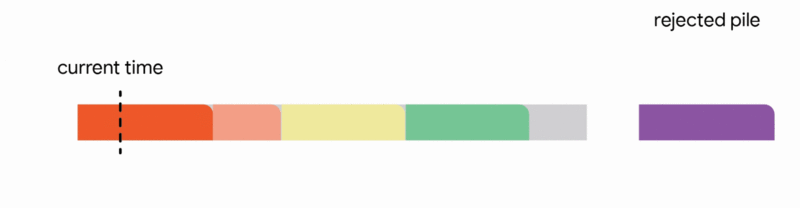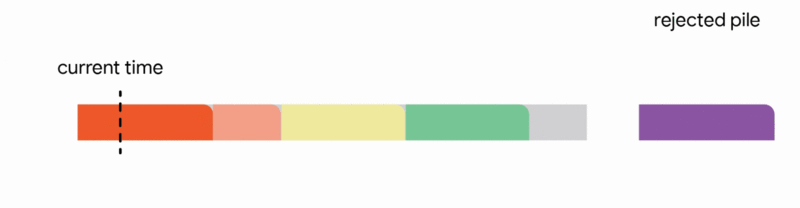
Our primary technical achievement demonstrates that a generalized version of this algorithm, adapted for arbitrary capacity profiles, yields the first constant competitive ratio for this problem. Specifically, we achieve a competitive ratio of 1/11. While guaranteeing the execution of approximately 9% of the optimal job set might seem conservative, this represents a worst-case assurance that remains valid even in the most adversarial operational scenarios.
Synthesis and Future Research Avenues
As cloud infrastructure continues its rapid evolution towards greater dynamism, the long-held assumption of static capacity within scheduling algorithms is becoming increasingly untenable. This research paper marks a seminal contribution by initiating the formal theoretical investigation into maximizing throughput under conditions of time-varying capacity, effectively bridging the divide between idealized scheduling models and the fluctuating realities inherent in modern data centers.
Despite our establishment of robust constant-factor approximation guarantees, opportunities for further advancement persist. The observable disparity between our derived 1/11 competitive ratio for online scheduling and the theoretical upper bound of 1/2 strongly suggests the potential existence of more performant algorithms. Future research could fruitfully explore the efficacy of randomized algorithms or investigate scenarios characterized by imperfect predictive knowledge of future capacity fluctuations, potentially yielding even more optimized solutions for practical, real-world applications.
Acknowledgements
This work represents a collaborative effort with Aniket Murhekar (University of Illinois at Urbana-Champaign), Zoya Svitkina (Google Research), Erik Vee (Google Research), and Joshua Wang (Google Research).