



August 20, 2025
Justin Y Chen, Student Researcher, and Morteza Zadimoghaddam, Research Scientist, Google Research
We unveil groundbreaking algorithms engineered to safeguard user privacy within data releases, substantially advancing the state-of-the-art in differentially private partition selection.
Quick links
Vast, user-centric datasets are indispensable for propelling AI and machine learning innovation. These datasets fuel advancements that directly enhance user experiences through superior services, heightened prediction accuracy, and personalized interactions. Collaborative efforts and data sharing accelerate research, cultivate novel applications, and enrich the global scientific community. However, harnessing the power of these datasets necessitates rigorous attention to potential data privacy risks.
The sophisticated process of isolating a specific, meaningful subset of unique elements for secure release from an extensive collection—based on their prevalence or prominence across individual contributions—is termed “differentially private (DP) partition selection.” This methodology identifies common elements (e.g., ubiquitous words in a large document corpus). By applying differential privacy to this selection, we ensure that an individual’s data contribution to the final list remains undetectable. This is achieved by introducing controlled noise, ensuring only items sufficiently common, even post-noise, are selected, thereby guaranteeing individual privacy. DP serves as a foundational step in numerous critical data science and machine learning tasks, including extracting vocabularies (or n-grams) from large private corpora for textual analysis and language modeling, analyzing data streams with privacy integrity, generating histograms from user data, and optimizing efficiency in private model fine-tuning.
When confronting colossal datasets, such as extensive user query logs, a parallel algorithm is not merely advantageous—it's essential. Instead of serial processing, a parallel algorithm partitions the problem into discrete sub-problems computable concurrently across multiple processors or nodes. This parallelization is paramount for managing the sheer volume of modern data, enabling the processing of datasets containing hundreds of billions of items and facilitating robust privacy guarantees without compromising data utility.
Our recent publication, “Scalable Private Partition Selection via Adaptive Weighting,” presented at ICML2025, introduces a high-performance parallel algorithm that democratizes DP partition selection for diverse data releases. This algorithm establishes new benchmarks, outperforming all existing parallel approaches and scaling to datasets hundreds of billions of records larger than those manageable by prior sequential methods. To foster widespread collaboration and innovation, we proudly open-source our DP partition selection implementation on GitHub.
How the algorithm works
The fundamental objective of DP partition selection is to maximize the count of unique items extracted from a union of data sets while rigorously upholding user-level DP. This principle allows for the secure preservation of highly prevalent items, which are associated with numerous users, for subsequent computational analyses, whereas items linked to a solitary user are excluded. Algorithm designers must meticulously balance privacy and utility, ensuring optimal item selection within the stringent constraints of differential privacy.
The standard paradigm: Weight, noise, and filter
The conventional methodology for differentially private partition selection comprises three foundational stages:
- Weight: Each item is assigned a "weight," typically indicative of its frequency or an aggregated measure across users, forming a weight histogram. A critical privacy prerequisite is "low sensitivity," ensuring that the cumulative weight contributed by any single user remains bounded. In a standard non-adaptive setting, users independently assign weights to items (e.g., the Gaussian weighting baseline), without knowledge of others' contributions.
- Noise: To enforce DP, random noise (e.g., Gaussian noise with a defined standard deviation) is systematically added to each item's calculated weight. This obfuscation masks precise counts, effectively preventing adversaries from inferring individual participation or data.
- Filter: A threshold, derived from the DP parameters, is applied. Only items whose noisy weights surpass this threshold are incorporated into the final output.
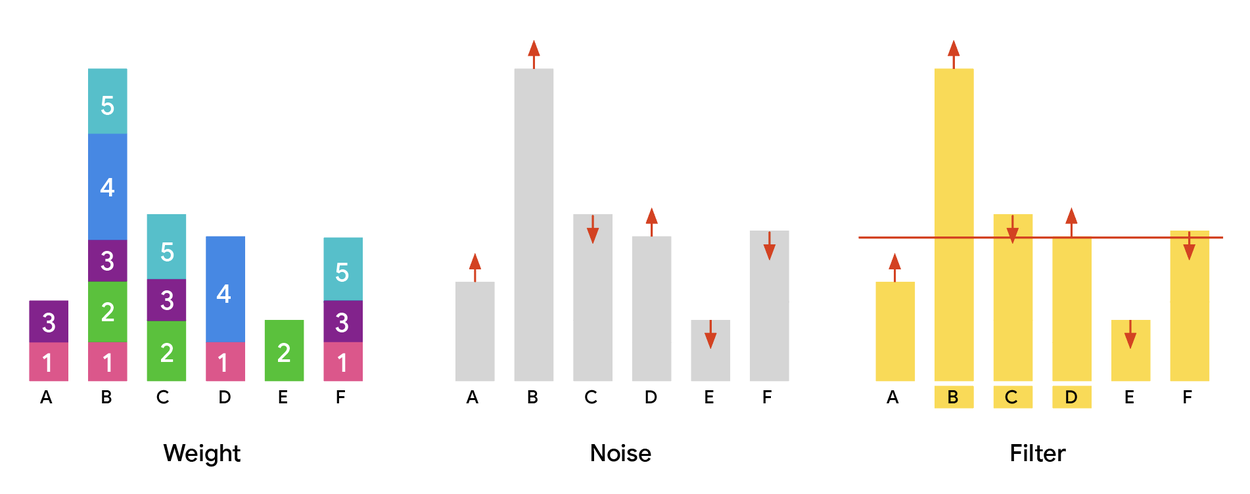
Illustrating the weight, noise, and filter paradigm. Across all plots, the x-axis denotes items (A–F), and the y-axis represents their assigned weights. The process begins with computing a weight histogram (left), followed by noise injection (center), culminating in the selection of items exceeding the noisy weight threshold (right).
Improving utility with adaptive weighting
A significant drawback of the standard, non-adaptive approach is the potential for "wastage." Highly frequent items might receive weights far exceeding the minimum required to cross the privacy threshold, leading to an inefficient "over-allocation" of weight. This surplus weight could be strategically redeployed to items situated just below the threshold, thereby increasing the total number of released items and substantially enhancing output utility.
We introduce adaptivity into the weight assignment mechanism to address this limitation. Unlike non-adaptive methods where user contributions are isolated, an adaptive design permits user-contributed weights to dynamically incorporate insights from other users' contributions. This intricate balance must be maintained without compromising privacy or computational efficiency.
Our novel algorithm, MaxAdaptiveDegree (MAD), executes strategic weight reallocation. It identifies items possessing substantial "excess weight" (significantly above the threshold) and redistributes a portion of this weight to "under-allocated" items (those falling just shy of the threshold). This adaptive redistribution ensures that a greater number of less-frequent items can successfully surpass the privacy threshold and be included in the output. Crucially, MAD preserves the identical low-sensitivity bounds and operational efficiency as the baseline, guaranteeing equivalent robust privacy protections and scalability within parallel processing frameworks (such as MapReduce-like systems), while delivering demonstrably superior utility.
Furthermore, we extend this adaptive framework to multi-round DP partition selection scenarios. We detail methods for the secure release of intermediate noisy weight vectors between rounds. This granular information enables enhanced adaptivity: we can systematically reduce future weight allocations to items that previously received excessive weight (and were thus prone to repeated over-allocation) or insufficient weight (making them unlikely to ever meet the threshold). This refines the weight distribution, maximizing utility without compromising privacy, and further increases the volume of items in the final output.
Experiments
We executed comprehensive experiments, benchmarking our MAD algorithm (with single or multiple iterations) against established scalable baselines for private partition selection.
As evidenced in the subsequent table, our MAD algorithm with merely two iterations (column MAD2R) consistently achieves state-of-the-art performance across numerous datasets—frequently yielding a substantially higher number of output items compared to alternative methods (even those employing more iterations), all while maintaining identical privacy guarantees.
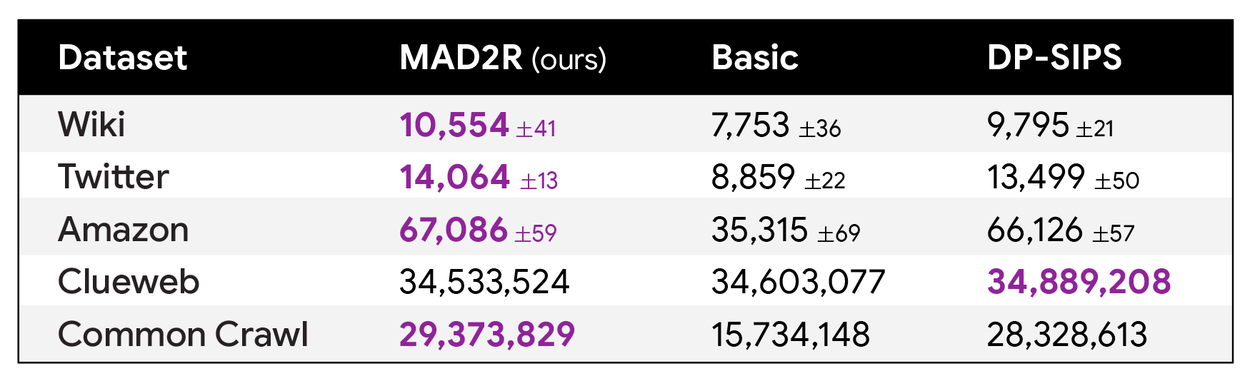
Comparative analysis of item counts returned by our algorithms: Two-round MAD (MAD2R) against scalable baselines including the uniformly weighted algorithm (“Basic”) and DP-SIPS, evaluated across nine publicly accessible datasets. By integrating novel adaptivity techniques, our two-round algorithm achieves state-of-the-art results across a broad spectrum of datasets.
Our comprehensive research paper provides theoretical underpinnings demonstrating that our single-round MAD algorithm consistently surpasses the single-round Gaussian weighting baseline. Empirical results corroborate this theoretical prediction, showcasing the superior performance of our new methodologies across diverse privacy parameter settings and hyperparameter configurations. An illustrative in-memory Python implementation of our algorithm is readily available in the open-source repository.
On the expansive, publicly available Common Crawl dataset (containing nearly 800 billion entries), we achieved record-breaking DP by treating each entry as a "user" and its constituent words as "items." Our two-iteration MAD algorithm produced an item set that successfully covered 99.9% of entries (where each entry contained at least one selected item) and 97% of database entries (corresponding to items present in the output), all while adhering to DP guarantees.
With only two iterations, our algorithm consistently delivered state-of-the-art outcomes across a wide array of parameter configurations. As our theoretical analysis predicted, the algorithm invariably outperformed the established baseline.
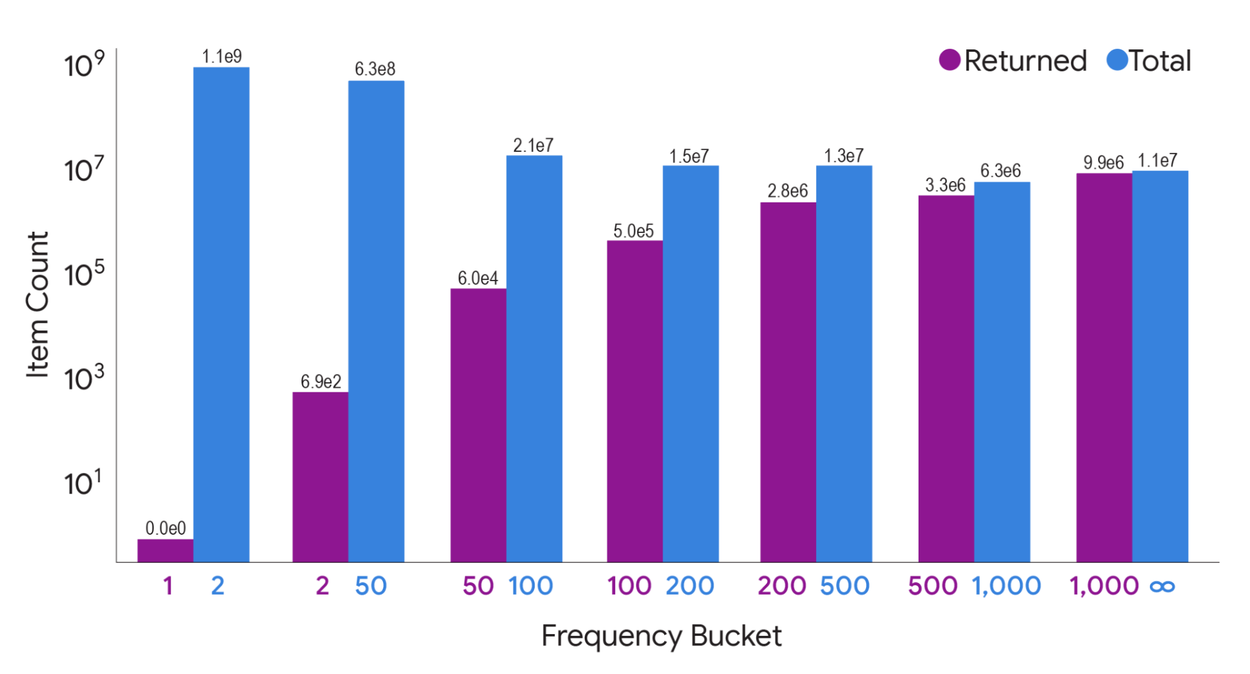
The quantity of items returned by our two-iteration MAD algorithm, categorized by frequency count (number of entries containing the item), on the Common Crawl dataset. While MAD omits low-frequency items that would compromise privacy, it successfully outputs the vast majority of items prevalent across numerous entries.
Conclusion
We introduce pioneering techniques to elevate the utility-privacy trade-off within DP partition selection algorithms. Our algorithm achieves state-of-the-art performance on datasets approaching trillion-entry scale. We anticipate this algorithm will empower practitioners to attain superior utility across their workflows while rigorously maintaining user privacy.
Acknowledgements
We extend our gratitude to Alessandro Epasto and Vincent Cohen-Addad from the Algorithm and Optimization team within Google Research for their invaluable contributions to this project.