


Wearable devices capture extensive life data, from heart rate to sleep patterns, holding immense potential for personalized health. However, understanding the context behind the metrics—the 'why' behind the 'what'—remains a significant challenge, limiting the full value of this technology. The primary obstacle is the lack of massive datasets pairing raw sensor recordings with descriptive text, making manual annotation infeasible. To overcome this, we require advanced models capable of directly learning the intricate connections between diverse sensor signals and natural language from available data.
Introducing SensorLM, a groundbreaking family of sensor-language foundation models presented in our paper, "SensorLM: Learning the Language of Wearable Sensors." Trained on an unparalleled 59.7 million hours of multimodal sensor data from over 103,000 individuals, SensorLM interprets and generates nuanced, human-readable descriptions from high-dimensional wearable data. This achieves a new state-of-the-art in understanding complex sensor information.
SensorLM translates complex, multimodal wearable sensor data into meaningful, natural language descriptions across statistical, structural, and semantic dimensions.
Train SensorLM Models for Peak Performance
We curated SensorLM's extensive training dataset by sampling nearly 2.5 million person-days of de-identified data from 103,643 participants across 127 countries, collected between March 1st and May 1st, 2024, via Fitbit or Pixel Watch devices. Participants explicitly consented to the use of their anonymized data for research, contributing to broader scientific understanding of health and human activity. To bypass the data annotation bottleneck, we engineered a novel hierarchical pipeline. This system automatically generates descriptive text captions by calculating critical statistics, identifying key trends, and articulating events directly from the sensor data. This innovative approach allowed us to construct the largest sensor-language dataset documented to date, significantly surpassing previous research efforts in scale.
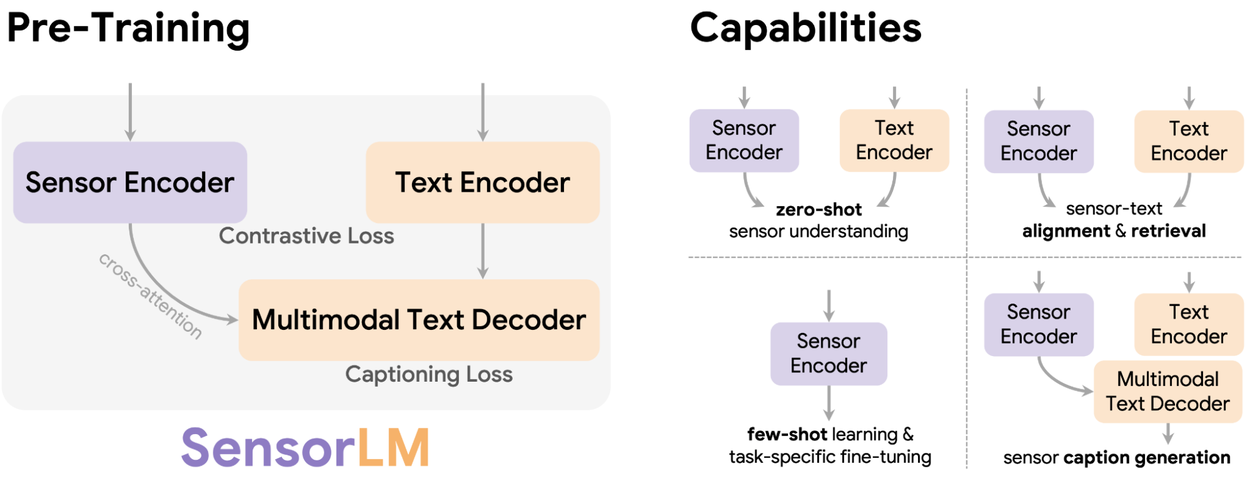
SensorLM pre-training unlocks advanced capabilities for personalized health insights, including zero-shot sensor understanding, robust sensor-text alignment and retrieval, efficient few-shot learning, and high-quality sensor caption generation.
SensorLM's architecture integrates prominent multimodal pre-training strategies, specifically contrastive learning and generative pre-training. Contrastive learning trains the model to accurately match sensor data segments with their correct text descriptions from a selection, enabling it to differentiate between various activities and states, such as distinguishing a "light swim" from a "strength workout." Generative pre-training equips the model to produce detailed text captions directly from sensor data, fostering a deep understanding of high-dimensional sensor signals to generate contextually rich descriptions. This synergistic integration creates a unified framework for SensorLM, cultivating a profound, multimodal comprehension of the sensor signal-language relationship.
Analyze SensorLM's Key Capabilities and Scaling Dynamics
We rigorously evaluated SensorLM across diverse real-world applications, including human activity recognition and healthcare scenarios. The results clearly demonstrate significant improvements over existing state-of-the-art models, establishing SensorLM as a leader in sensor data interpretation.
Master Activity Recognition and Retrieval with SensorLM
SensorLM excels in tasks requiring minimal labeled data. It achieves exceptional zero-shot classification for activities, accurately identifying 20 distinct activities without any specific fine-tuning. Furthermore, it demonstrates remarkable few-shot learning capabilities, rapidly adapting to new tasks with only a few examples, ensuring high adaptability for new users and applications. SensorLM also powers advanced cross-modal retrieval, enabling seamless understanding between sensor data and textual descriptions. Users can query specific sensor patterns using natural language or obtain descriptions based on sensor input, facilitating in-depth expert analysis. Detailed findings are available in our comprehensive paper.

In zero-shot human activity recognition, SensorLM achieves superior performance across tasks (measured by AUROC), while baseline LLMs perform near random chance.
Harness SensorLM's Advanced Generative Capabilities
Beyond its potent classification abilities, SensorLM delivers exceptional caption generation performance. The model accurately produces hierarchical and contextually relevant captions directly from high-dimensional sensor signals captured by wearable devices. Experimental results confirm that SensorLM's generated captions are more coherent and factually precise than those produced by powerful, general-purpose large language models.
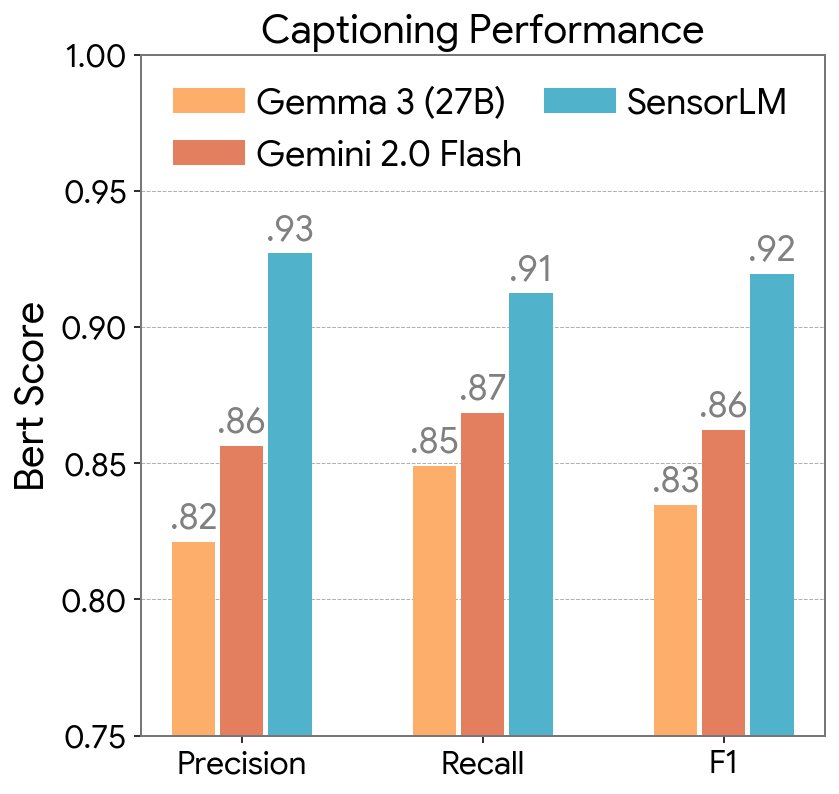
Captioning performance of SensorLM and baselines, measured by BERTScore (Precision, Recall, F1).
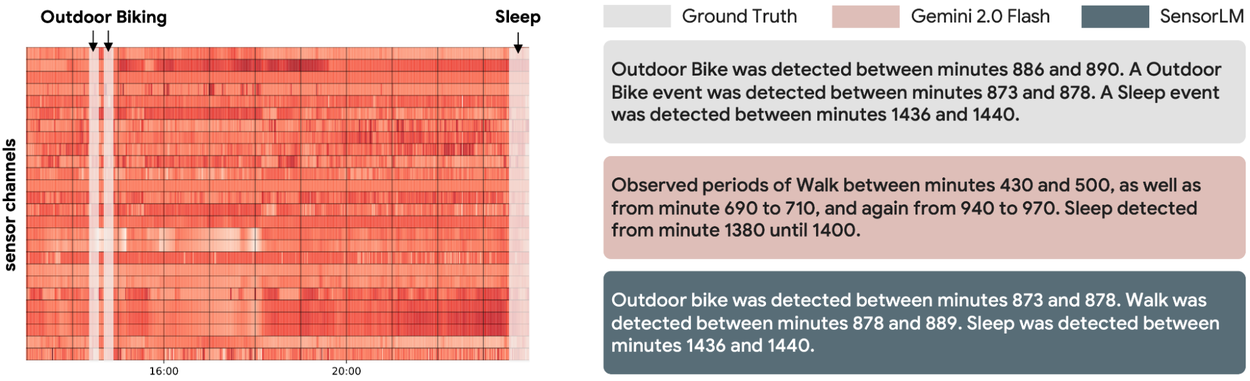
Left: Input wearable sensor data. Right: The ground truth description and descriptions generated by different models. SensorLM produces coherent and accurate captions directly from sensor data, offering superior detail and precision compared to generic language models.
Observe SensorLM's Powerful Scaling Behavior
Our extensive experiments reveal that SensorLM's performance consistently escalates with increased data, larger model sizes, and greater computational resources, adhering to established scaling laws. This sustained improvement trajectory indicates that the full potential of large-scale sensor-language pre-training is yet to be realized, underscoring the significant value in continued research within this paradigm.

Through systematic scaling experiments of SensorLM models, we demonstrate that enhanced compute (left), data (middle), and model size (right) consistently elevate performance in zero-shot activity recognition.
SensorLM: The Future of Wearable Data Understanding
Our research establishes a robust foundation for interpreting wearable sensor data through natural language, powered by a novel hierarchical captioning pipeline and the most extensive sensor-language dataset assembled to date. The SensorLM model family represents a significant leap forward in transforming personal health data into understandable and actionable insights. By enabling AI to comprehend the language of our bodies, we move beyond basic metrics toward genuinely personalized wellness guidance. Future developments will expand pre-training data into critical areas like metabolic health and detailed sleep analysis, addressing the complexities of consumer health devices. We foresee SensorLM powering next-generation digital health coaches, clinical monitoring tools, and personal wellness applications, offering intelligent advice through natural language interaction and generation. Any products or applications developed from this foundational research will undergo thorough assessment for relevant clinical and regulatory considerations.
Acknowledgments for SensorLM Research
This significant research effort represents a collaborative achievement across Google Research, Google Health, Google DeepMind, and our valued partner teams. The following researchers were instrumental in this work: Yuwei Zhang, Kumar Ayush, Siyuan Qiao, A. Ali Heydari, Girish Narayanswamy, Maxwell A. Xu, Ahmed Metwally, Shawn Xu, Jake Garrison, Xuhai Xu, Tim Althoff, Yun Liu, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Cecilia Mascolo, Xin Liu, Daniel McDuff, and Yuzhe Yang. We extend our sincere gratitude to all participants who generously contributed their data, enabling this groundbreaking study.