



As AI technologies advance, truly helpful agents will better anticipate user needs. For mobile experiences to be genuinely helpful, underlying models must understand user interactions. By comprehending current and past tasks, models gain context to predict potential next actions. For example, if a user searched for music festivals in Europe and now seeks a flight to London, an agent can offer to find London festivals on those dates.
Large multimodal LLMs currently excel at understanding user intent from UI trajectories. However, employing LLMs for this task often involves slow, costly server communication and risks exposing sensitive information.
Our recent paper, “Small Models, Big Results: Achieving Superior Intent Extraction Through Decomposition”, presented at EMNLP 2025, investigates using small multimodal LLMs (MLLMs) for on-device understanding of web and mobile user interaction sequences. We decompose intent understanding into two stages: first, summarizing each screen individually, then extracting intent from the sequence of generated summaries, making the task more manageable for small models. We also formalize evaluation metrics, demonstrating results comparable to much larger models, highlighting its potential for on-device applications. This research builds upon our team's prior work in user intent understanding.
Research Highlights: Decomposed Intent Extraction
We introduce a decomposed workflow for understanding user intent from interactions. At inference, the model executes two primary steps: first, it independently summarizes each individual screen interaction; second, it uses these summaries as an event sequence to predict the overall intent of the UI trajectory.
Individual Screen Summarization
The first stage leverages a small multimodal LLM to summarize every individual interaction.
Utilizing a sliding window of three screens (previous, current, next), the model addresses these critical questions:
- What is the relevant screen context? Provide a concise list of salient details from the current screen.
- What did the user just do? List the actions the user performed during this interaction.
- Speculate: What is the user attempting to achieve with this interaction?
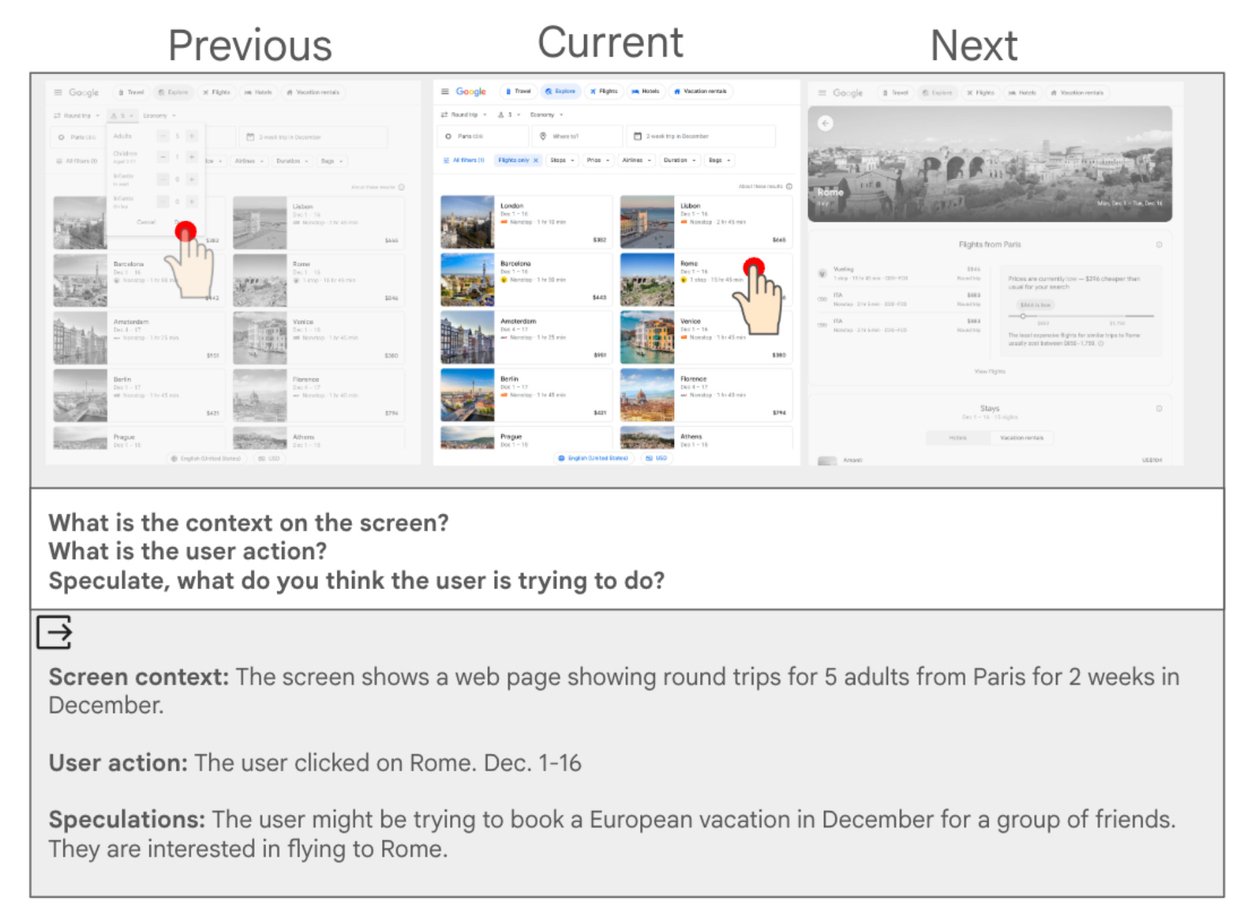
The initial stage of the decomposed workflow involves examining surrounding screens for each screenshot-action pair. We query screen context, user actions, and user intentions. The example at the bottom demonstrates a potential LLM-generated summary answering these three questions, serving as input for the second stage.
Intent Extraction from Summaries
The second stage employs a fine-tuned small model to extract a single, concise intent statement from the screen summaries.
We identified several techniques that significantly enhance performance:
- Fine-tuning: Providing examples of effective intent statements guides the model to prioritize crucial information within summaries and discard irrelevant details. We utilize publicly available automation datasets for training, as they offer robust examples pairing intents with action sequences.
- Label Preparation: Summaries may omit details. To prevent the model from hallucinating missing information, we preprocess training intents by removing any elements not present in the summaries, using a separate LLM call.
- Dropping Speculations: While speculations aid first-stage summary completeness, they can confuse the second-stage intent extractor. Therefore, we exclude them during the second stage. This strategy, though seemingly counterintuitive, demonstrably improves performance.
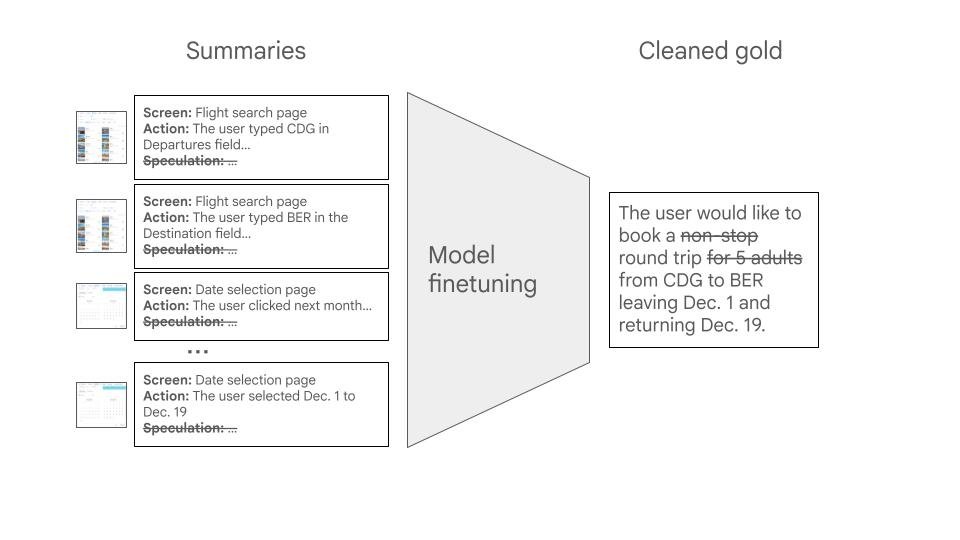
The second stage of our decomposed workflow utilizes a fine-tuned model that processes summaries from the first stage to output a concise intent statement. We exclude all speculative content and meticulously clean training labels to prevent hallucinations.
Rigorous Evaluation Approach
We employ the Bi-Fact approach to assess predicted intent quality against reference intents. This method uses a separate LLM call to break down intents into indivisible "atomic facts." For instance, "a one-way flight" is an atomic fact, while "a flight from London to Kigali" comprises two. We then quantify the number of reference facts entailed by the predicted intent and vice versa, establishing precise measures of precision (correct predicted facts) and recall (correctly predicted true facts), leading to the calculation of the F1 score.

Fact Coverage Analysis assesses how effectively reference facts are captured in predicted intents (left) and if predicted facts align with the reference intent (right).
Analyzing atomic facts also reveals how different stages of the decomposed approach contribute to errors. Below, we illustrate how we track missed details and hallucinations at each stage by examining fact flow through the system.
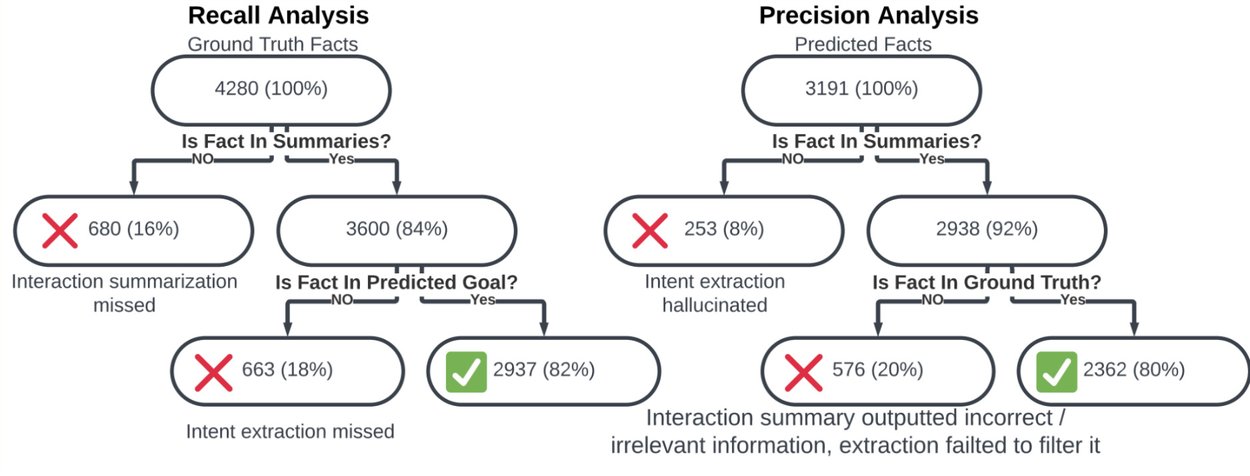
Error propagation analysis tracks recall and precision across both model stages.
Exceptional Performance Results
Our decomposed approach, which summarizes screens independently before extracting intent, significantly aids small models. Compared to standard methods like chain-of-thought prompting (CoT) and end-to-end fine-tuning (E2E), our method achieves superior results on both mobile and web trajectories, performing well with both Gemini and Qwen2 base models. Notably, the decomposed approach with the Gemini 1.5 Flash 8B model delivers performance comparable to Gemini 1.5 Pro at a significantly lower cost and higher speed. Explore additional experiments in the full paper.
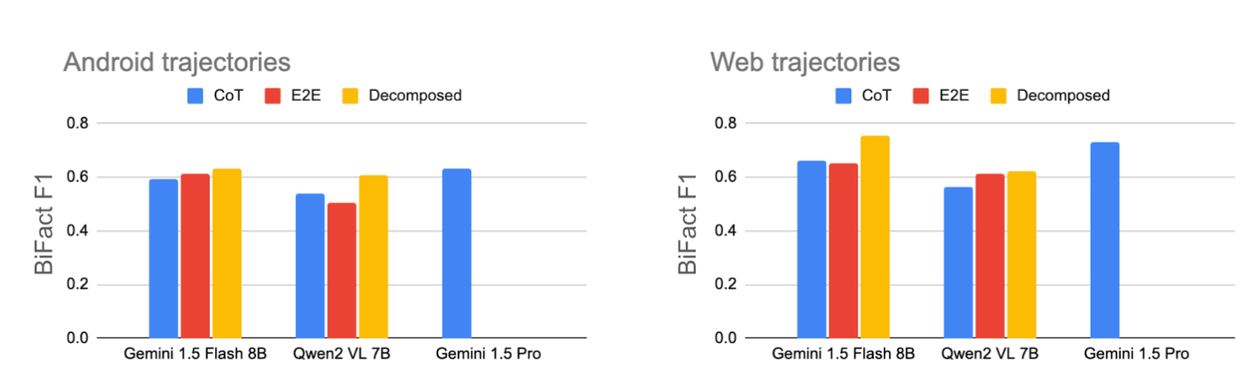
Our decomposed method consistently outperforms baseline chain-of-thought prompting (CoT) and end-to-end fine-tuning (E2E) in Bi-Fact F1 scores. On mobile datasets, its performance rivals the large Gemini Pro model.
Conclusion and Future Outlook
We demonstrated that a decomposed approach to trajectory summarization effectively enhances intent understanding with small models. As AI models advance and mobile device processing power increases, we anticipate on-device intent understanding becoming a foundational element for numerous assistive mobile features.
Acknowledgments
We express our gratitude to our coauthors: Noam Kahlon, Joel Oren, Omri Berkovitch, Sapir Caduri, Ido Dagan, and Anatoly Efros.