



Cyrus Rashtchian, Research Lead, and Da-Cheng Juan, Software Engineering Manager, Google Research
We present a groundbreaking framework for evaluating Retrieval Augmented Generation (RAG) systems by introducing the novel concept of sufficient context. This empowers us to precisely classify RAG instances, diagnose system failures, and engineer methods to dramatically reduce AI hallucinations.
Retrieval Augmented Generation (RAG) significantly elevates Large Language Models (LLMs) by equipping them with vital external context. In a question-answering (QA) scenario, a RAG system provides the LLM with synthesized information from diverse sources, including public web pages, private document repositories, and knowledge graphs. The ideal outcome is an accurate answer or a clear declaration of insufficient information.
A primary obstacle in RAG systems is the tendency to generate hallucinated, factually incorrect information. Moreover, previous research predominantly assessed context relevance, overlooking a more critical metric: whether the context actually furnishes the necessary information for the LLM to formulate a correct answer.
In our seminal publication, “Sufficient Context: A New Lens on Retrieval Augmented Generation Systems,” presented at ICLR 2025, we meticulously explore the principle of 'sufficient context' within RAG architectures. We establish definitive criteria for determining when an LLM possesses adequate information to answer a query accurately. Our research scrutinizes the impact of context availability on factual integrity and introduces a robust method for quantifying context sufficiency. This advanced methodology illuminates the determinants of RAG system efficacy and pinpoints the precise conditions under which they achieve success or encounter failure.
Furthermore, these foundational insights have propelled the integration of our LLM Re-Ranker within the Vertex AI RAG Engine. This feature empowers users to optimize retrieved snippets based on query relevance, culminating in superior retrieval metrics such as nDCG and enhanced RAG system accuracy.
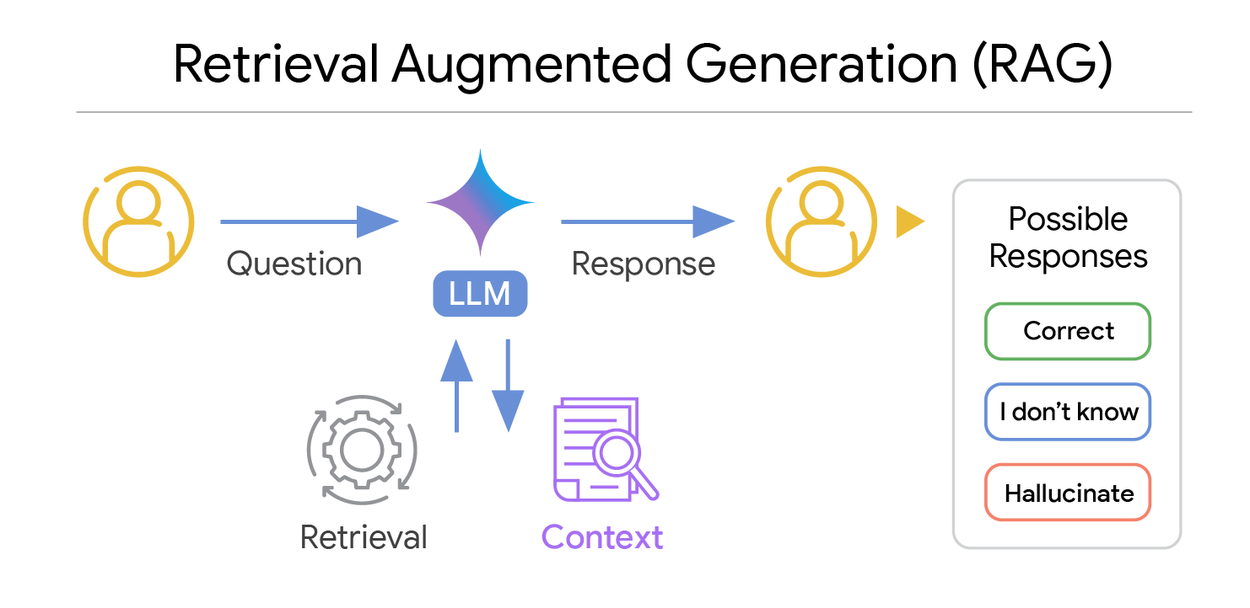
In a RAG system, an LLM leverages retrieved context to formulate its response to an input question.
Main conceptual contribution: Sufficient context
We meticulously define context as “sufficient” when it encompasses all essential information for a definitive query response. Conversely, “insufficient” context lacks critical details, is incomplete, inconclusive, or contains contradictory elements. Consider this illustrative example:
Input query: The error code for “Page Not Found” is named after room 404, which had stored the central database of error messages in what famous laboratory?
- Sufficient context: The “Page Not Found” error, commonly represented as a 404 code, derives its name from Room 404 at CERN, the European Organization for Nuclear Research. This specific room housed the central repository for error messages, including the designation for a missing page.
- Insufficient context: A 404 error, or “Page Not Found” error, signifies that the web server cannot locate the requested page. This can occur due to several factors, such as URL misspellings, page relocation or deletion, or temporary website operational issues.
While the latter context is highly relevant to the user's query, it fails to provide the answer, rendering it insufficient.
Developing a sufficient context autorater
Leveraging this definition, we engineered an advanced LLM-powered automatic rater (“autorater”) to rigorously assess query-context pairings. To validate the autorater's performance, human experts initially evaluated 115 question-and-context scenarios, classifying each as providing sufficient or insufficient context. This served as our authoritative “gold standard.” Subsequently, the LLM evaluated the identical question-context sets, outputting a binary “true” for sufficient context or “false” for insufficient context.
To optimize the model's proficiency in this task, we refined the prompts using sophisticated prompting strategies, including chain-of-thought reasoning and the incorporation of 1-shot examples. We meticulously measured classification accuracy by comparing the LLM's true/false labels against the gold standard.
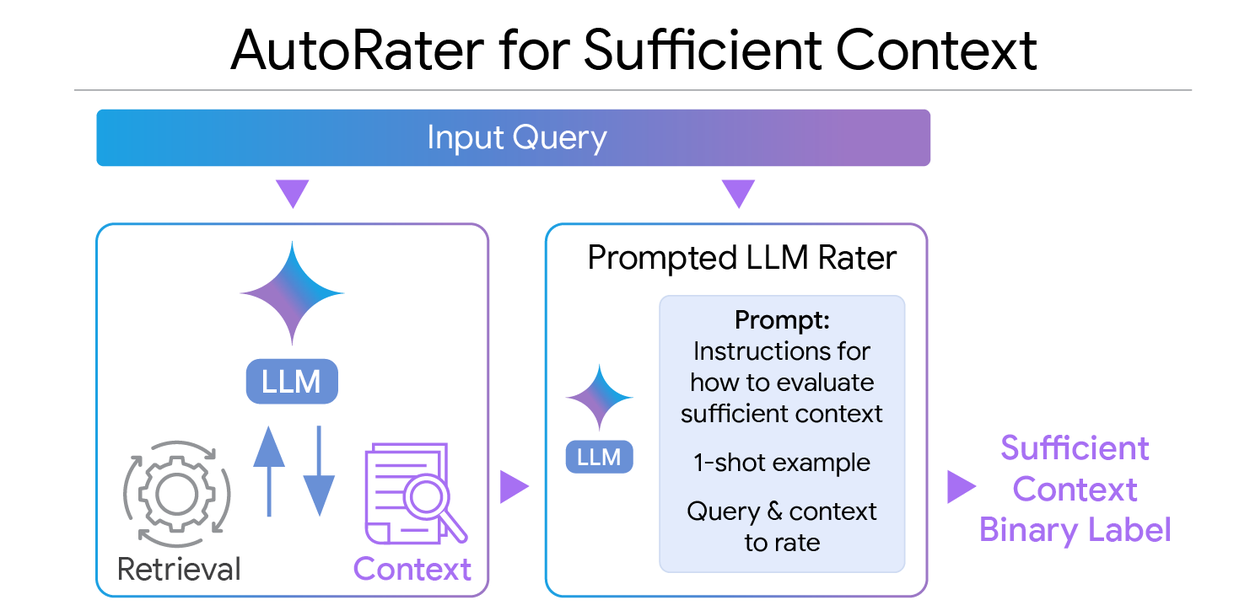
Our automated rating mechanism (autorater) for assessing sufficient context. A prompted LLM evaluates query-context pairs, generating a binary sufficient/insufficient context label.
Employing our refined prompt, we achieved exceptional classification accuracy for sufficient context, exceeding 93%. Notably, the most effective method identified was a prompted Gemini 1.5 Pro, requiring no fine-tuning. As comparative benchmarks, we demonstrate that FLAMe (a fine-tuned PaLM 24B model) exhibits slightly lower performance but offers superior computational efficiency. We also benchmark against methods relying on ground truth answers, such as TRUE-NLI (a fine-tuned entailment model) and a straightforward “Contains GT” approach. Gemini's superior performance is attributed to its advanced language comprehension capabilities.

Accuracy in classifying sufficient context, measuring the concordance between automated methods and human-annotated labels.
This autorater facilitates scalable instance labeling and sophisticated analysis of model responses based on context sufficiency.
Key insights into RAG systems
Leveraging our sufficient context autorater, we conducted a comprehensive analysis of diverse LLMs and datasets, yielding critical findings:
- State-of-the-art large models: Advanced models such as Gemini, GPT, and Claude excel when presented with sufficient context but struggle to identify and circumvent incorrect answers stemming from insufficient context.
- Smaller open-source models: Our research highlights a significant propensity for hallucination and abstention in open-source models, even when context is adequate for correct answers.
- Insufficient context utility: Paradoxically, models sometimes generate correct answers despite insufficient context. This indicates that even limited context can be beneficial, bridging knowledge gaps or clarifying query ambiguities.
Actionable insights: Our findings provide concrete strategies for RAG system enhancement. Recommendations include: (i) implementing a pre-generation sufficiency check, (ii) optimizing context retrieval and re-ranking, or (iii) fine-tuning abstention thresholds using confidence and context signals.
Diving into the research behind sufficient context
Our analysis reveals that numerous standard benchmark datasets contain a substantial number of insufficient context instances. We examined three prominent datasets: FreshQA, HotPotQA, and MuSiQue. Datasets featuring a higher proportion of sufficient context instances, such as FreshQA, are typically those where context is derived from human-curated supporting documents.
A prime illustration is Example 182 from FreshQA: “How many food allergens with mandatory labeling are there in the United States?” The correct answer is nine, following the 2023 inclusion of sesame. The dataset’s supporting document, the Wikipedia article on Food Allergies, contains a table under “Regulation of labeling” that lists the nine mandatory allergens.
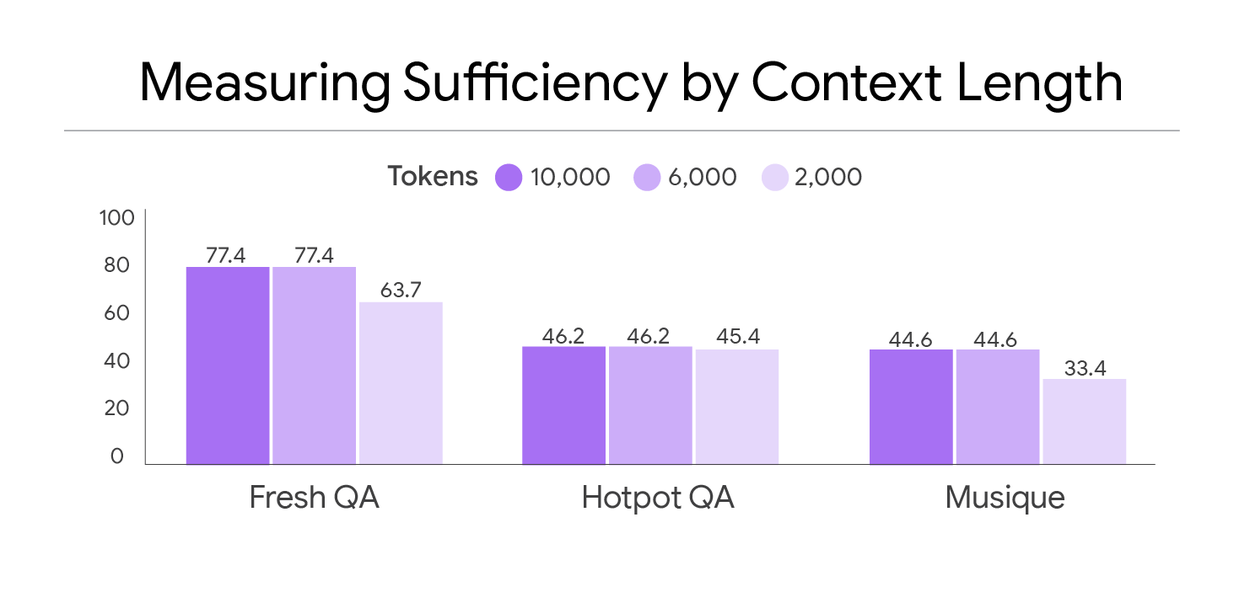
Comparison of the percentage of examples with sufficient context (y-axis) across three datasets (x-axis).
Adding context leads to more hallucinations
A striking finding is that RAG, while generally improving performance, paradoxically diminishes the model's ability to abstain appropriately. The infusion of additional context appears to elevate the model's confidence, thereby increasing its susceptibility to hallucination over abstention.
To investigate this phenomenon, we utilized Gemini to meticulously rate each model response against the spectrum of possible ground truth answers, categorizing each as “Correct,” “Hallucinate” (incorrect), or “Abstain” (e.g., “I don’t know”). Our analysis reveals, for instance, that Gemma's incorrect answer rate escalates from 10.2% with no context to a substantial 66.1% when presented with insufficient context.
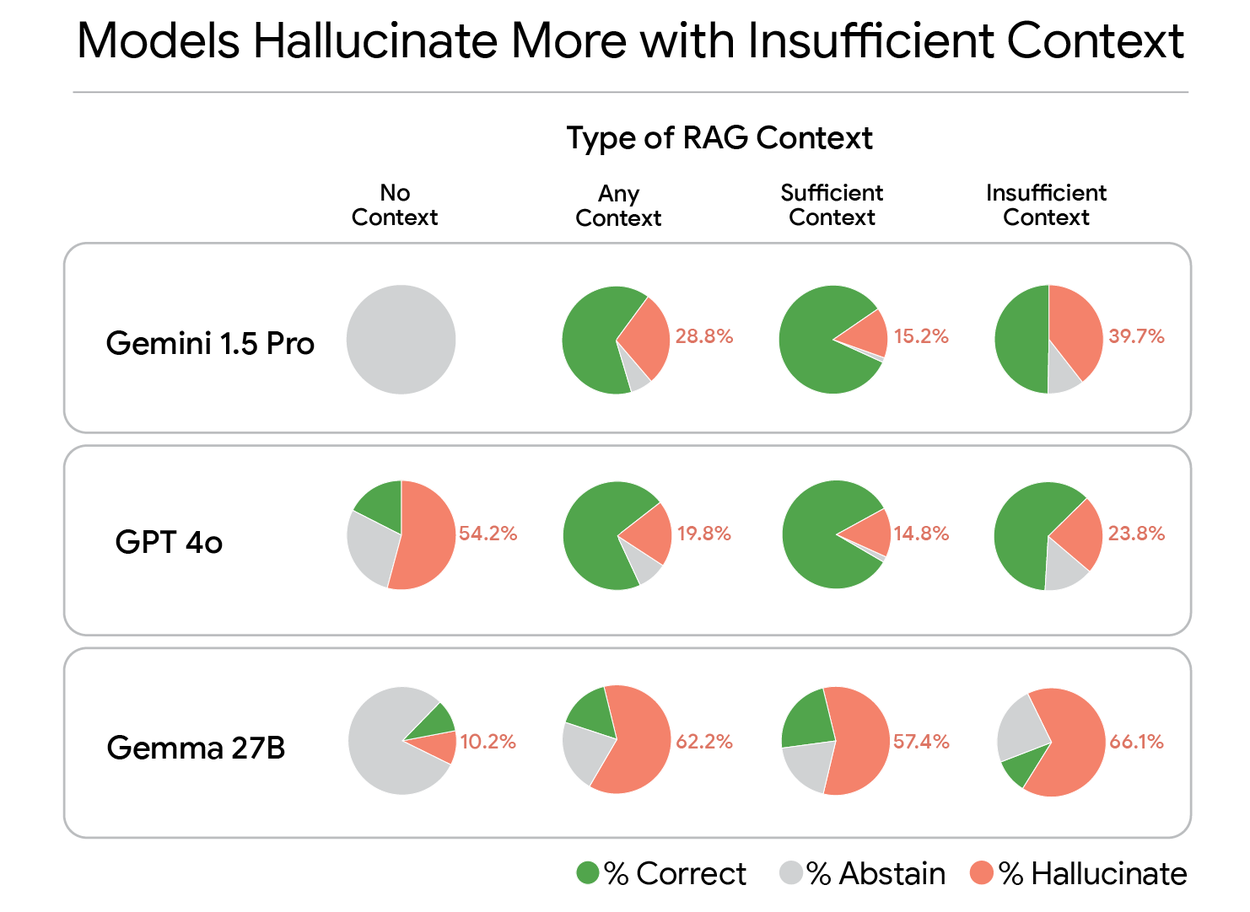
In-depth analysis of three LLMs across four distinct RAG configurations.
Selective generation to reduce hallucinations
As a further innovation, we introduce a “selective generation” framework that strategically employs sufficient context information to prompt abstention. We employ key metrics: selective accuracy, quantifying the proportion of correct answers among those generated, and coverage, representing the fraction of questions answered.
Our selective generation methodology integrates the sufficient context signal with the model's self-assessed confidence scores to guide judicious abstention decisions. This offers a more nuanced approach than simply abstaining when context is insufficient, acknowledging that LLMs can sometimes produce accurate responses even with limited data. We leverage these signals to train a logistic regression model for hallucination prediction. Subsequently, we establish a coverage-accuracy trade-off threshold to govern when the model should abstain from responding.
play silent looping videopause silent looping videounmute videomute videoThe operational pipeline for our selective generation technique designed to mitigate AI hallucinations.
Our abstention strategy is guided by two primary signals:
- Self-rated confidence: We employ two methodologies: P(True) involves multiple answer samplings and prompts the model to classify each sample as correct or incorrect. P(Correct) is suitable for scenarios where extensive querying is resource-intensive; it entails obtaining the model's response and its estimated probability of correctness.
- Sufficient context signal: We utilize a binary label from an autorater model (FLAMe) indicating context sufficiency. Crucially, this label is determinable without the ground truth answer, enabling its use during query processing.
Our findings conclusively demonstrate that this integrated approach yields a superior selective accuracy-coverage trade-off compared to relying solely on model confidence. By incorporating the sufficient context label, we achieve significant improvements in accuracy for answered questions, with gains reaching up to 10%.
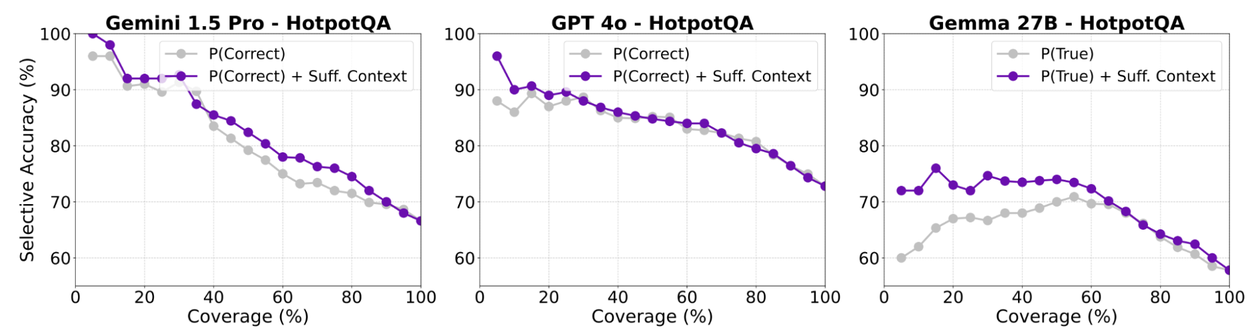
Selective accuracy (accuracy on answered questions) versus coverage (fraction of answered questions).
Conclusion
Our research provides profound new insights into LLM behavior within RAG systems. By conceptualizing and operationalizing sufficient context, we have created an invaluable instrument for analyzing and refining these critical AI architectures. We have elucidated that insufficient context is a significant driver of hallucinations in RAG systems and have demonstrated that selective generation effectively mitigates this issue. Future investigations will focus on how disparate retrieval methodologies impact context sufficiency and how retrieval quality signals can elevate post-training model performance.
Acknowledgments
This research represents a significant collaboration with Hailey Joren (lead student author), Jianyi Zhang, Chun-Sung Ferng, and Ankur Taly. We extend our gratitude to Mark Simborg and Kimberly Schwede for their invaluable support in writing and design, respectively. We also acknowledge Alyshia Olsen for her exceptional assistance in creating the graphics.