


September 23, 2025
Rajat Sen, Research Scientist, and Yichen Zhou, Software Engineer, Google Research
We unveil a groundbreaking technique for time-series forecasting, leveraging continued pre-training to empower foundation models with rapid adaptation to in-context examples during inference.
Elevate your business operations with powerful time-series forecasting, crucial for predicting inventory, energy consumption, and market trends. Historically, this demanded bespoke, expert-built models for each distinct task, a resource-intensive and time-consuming process.
The advent of zero-shot learning presented a significant advancement. Our prior innovation, TimesFM, established a pre-trained foundation model capable of accurate forecasting without task-specific fine-tuning. Imagine enhancing this capability further: what if a few illustrative examples could dramatically improve forecast precision? For instance, predicting highway traffic gains immense accuracy by incorporating data from adjacent routes or historical patterns from the same route weeks prior. Standard supervised fine-tuning, while effective, reintroduces the very complexities we aim to surmount with zero-shot approaches.
Our latest research, detailed in "In-Context Fine-Tuning for Time-Series Foundation Models," presented at ICML 2025, introduces a revolutionary method transforming TimesFM into a sophisticated few-shot learner. This novel strategy utilizes continued pre-training to equip the model with the ability to learn dynamically from a sparse set of examples at inference time, delivering performance akin to supervised fine-tuning without the user-imposed training overhead.

Analogous to few-shot prompting in Large Language Models (LLMs) (left), a time-series foundation model effectively leverages multiple related in-context time series examples for enhanced predictions (right). The highlighted orange region delineates the model's input parameters.
Redesigning the model
TimesFM employs a patched decoder architecture. It discretizes contiguous timepoints into "patches," which are then converted into input tokens. A transformer stack processes these input tokens, generating output tokens. Subsequently, a shared multilayer perceptron (MLP) translates each output token back into a time series of 128 timepoints. For advanced insights, explore the foundational TimesFM architecture and tokenization methodology with its tokenization and transformer components.
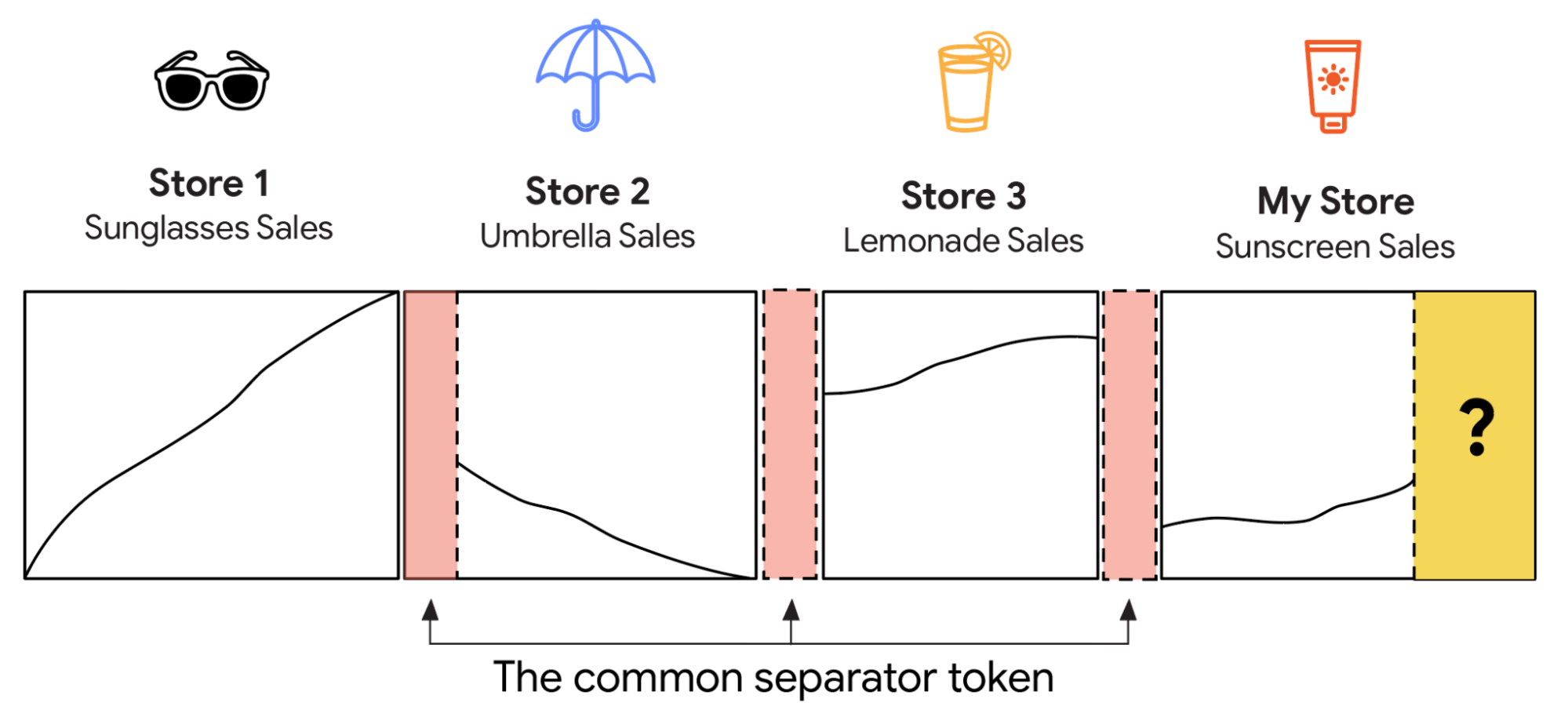
To construct TimesFM-ICF (In-Context Fine-tuning), we initiate with the core TimesFM model and augment its pre-training by incorporating novel context: the forecasting history alongside all provided in-context examples. Crucially, the model must distinguish between these distinct data streams. Imagine feeding the model sales data from sunglasses and umbrella stores; naive concatenation risks conflating trends. For instance, a rising trend in one and a declining trend in another could be misinterpreted as a single, oscillating pattern.
We mitigate this by introducing a unique, learnable "common separator token" after each distinct data segment. This token acts as a digital delimiter, preventing the model from merging disparate examples. Upon encountering a separator token associated with a previously seen example, the model refrains from conflating it with current prediction data. Theoretically, this enables the model to extract patterns from historical examples and apply them to contemporary forecasts. For example, it could infer that consistent directional trends across multiple stores suggest a similar trajectory for a new product's sales.
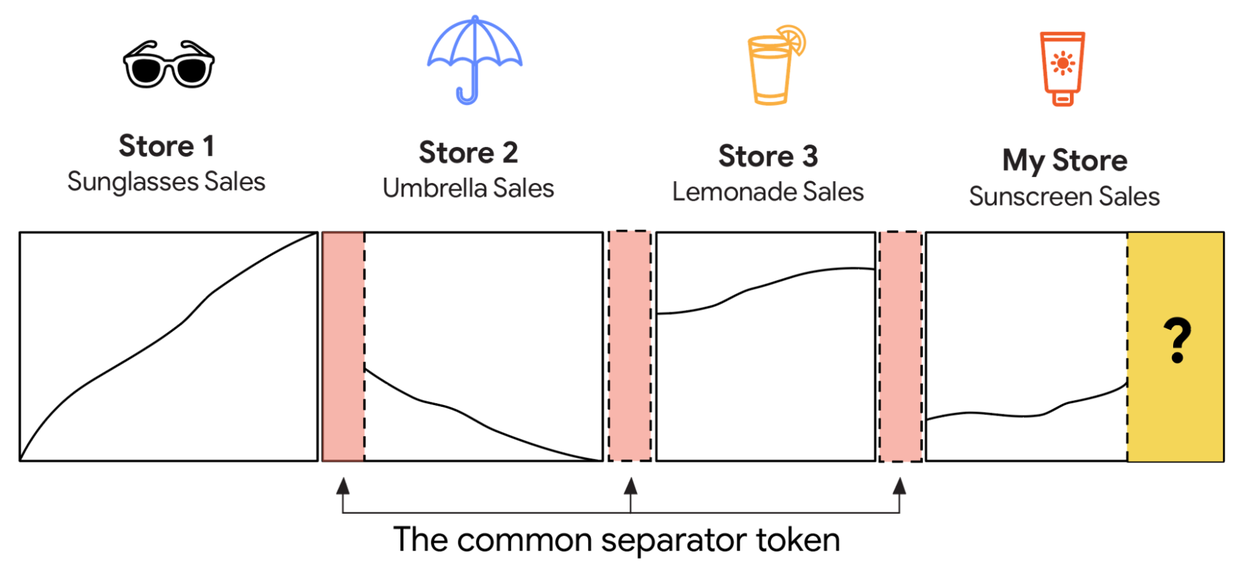
Naive concatenation of in-context examples, without distinct separators, risks misinterpreting multiple monotonic trends as a single, irregular pattern.
Because the separator tokens and their attention mechanisms are novel to TimesFM, our subsequent step involves continued pre-training of the base model to integrate these new elements. The process is straightforward: we construct a new dataset incorporating both in-context examples and separator tokens, then apply standard decoder-only next-token prediction training. Inputs are processed by the MLP layer, which generates tokens. These tokens are then fed into a causal self-attention (CSA) layer. This CSA mechanism enables the model to "attend to" information from preceding tokens, a critical capability in time-series forecasting as it prevents future data leakage. The CSA then outputs to a feed-forward network (FFN). This CSA and FFN sequence is replicated across multiple layers – forming the stacked transformers – before the final result connects to the output MLP layer. Explore further on attention masking and feed-forward networks.
play silent looping videopause silent looping videounmute videomute videoTimesFM-ICF utilizes a decoder-only architecture for time-series forecasting, employing distinct common separator tokens to differentiate between in-context examples and the primary task history.
Testing the model
We rigorously evaluated TimesFM-ICF across 23 distinct datasets, previously unseen during any training phase. Each benchmark dataset comprises multiple time series. For forecasting a specific time series, we initiate with its immediate historical data, then sample sequences from its complete history and the histories of other related time series within the same dataset as in-context examples. This methodology guarantees the relevance of the in-context examples while preventing data leakage.
The accompanying chart illustrates the geometric mean (GM) aggregation of mean absolute scaled errors (MASE). These errors are normalized against a naïve baseline that repeats the last seasonal pattern. We present results against two key baselines:
- TimesFM (Base): The original pre-trained model serving as our starting point.
- TimesFM-FT: An enhanced version of TimesFM (Base) subjected to supervised fine-tuning on each dataset's training split, subsequently evaluated on its corresponding test split. This represents the previous state-of-the-art for domain adaptation.
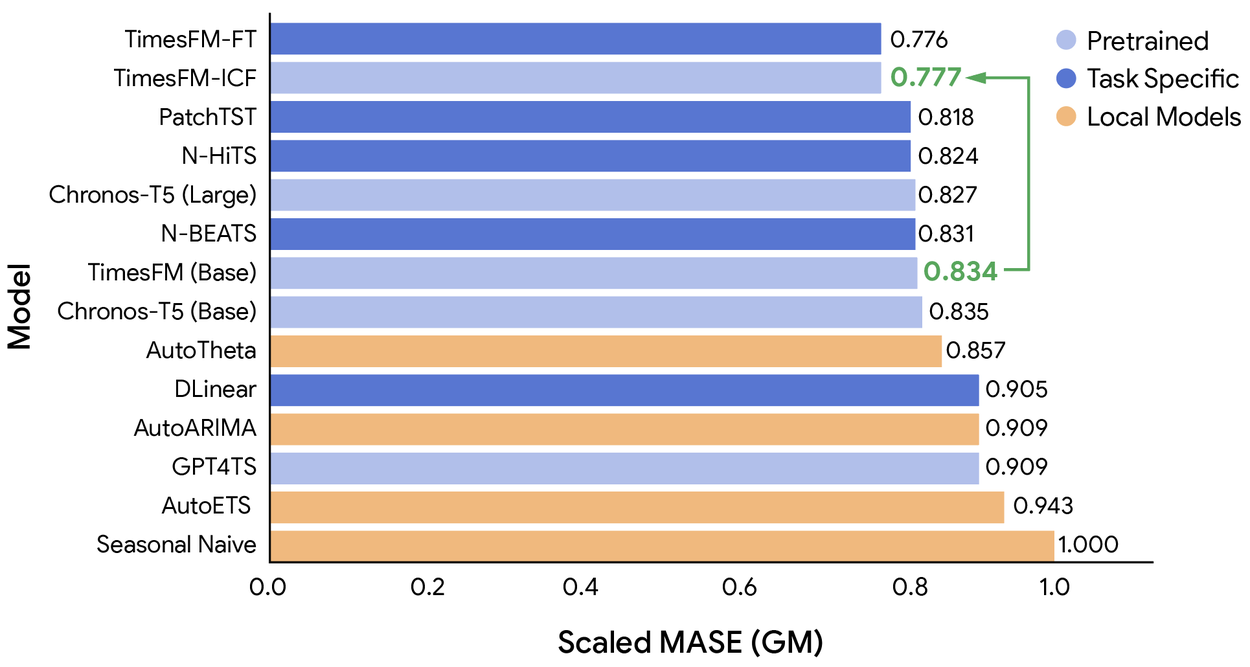
TimesFM-ICF demonstrates superior performance compared to TimesFM (Base) across numerous task-specific models, achieving parity with TimesFM-FT, which undergoes dataset-specific fine-tuning.
TimesFM-ICF achieves a 6.8% improvement in accuracy over TimesFM (Base). Remarkably, it matches the performance of TimesFM-FT without the necessity of executing complex supervised fine-tuning procedures.
Beyond enhanced accuracy, TimesFM-ICF exhibits other advantageous characteristics. It aligns with our expectations: providing more in-context examples increases forecast precision, albeit at the expense of slightly longer inference times. Furthermore, TimesFM-ICF showcases superior context utilization when contrasted with a pure long-context model lacking in-context learning capabilities.
The future: More accessible and powerful forecasting
This innovative approach holds profound implications for real-world applications, enabling organizations to deploy a single, highly robust, and adaptable forecasting model. Instead of initiating extensive ML projects for new forecasting challenges, such as predicting demand for novel products, businesses can simply supply the model with a few relevant examples. This facilitates immediate access to state-of-the-art, specialized forecasts, significantly reducing costs, accelerating decision-making and innovation, and democratizing access to advanced forecasting technologies.
We anticipate a dynamic future for this research, particularly in developing automated strategies for optimal in-context example selection. By enhancing the intelligence and adaptability of foundation models, we empower a broader user base to make more informed, data-driven decisions.
Acknowledgements
This pioneering research was spearheaded by then-student researcher Matthew Faw, in collaboration with Google Research colleagues Abhimanyu Das and Ivan Kuznetsov. The publication of this blog post was made possible through the invaluable contributions of editors Mark Simborg and Kimberly Schwede.