



Machine learning (ML) has grown a lot. Powerful computer models and training methods help. But even big language models have trouble learning new things over time. This is called continual learning. It means a model can learn new skills without forgetting old ones.
The human brain is great at learning. It changes to learn from new experiences. This is like neuroplasticity. Without it, we only remember what's happening right now. Current language models are similar. They only know what fits in their text window or what they learned before.
If you just keep updating a model with new data, it often forgets old tasks. This is called catastrophic forgetting. Some try to fix this with different model parts or training rules. But we have treated the model's structure and its training rules as separate. This stops us from making a smart, efficient learning system.
Our paper, \u0022Nested Learning: The Illusion of Deep Learning Architectures\u0022, introduces Nested Learning. It connects model structure and training. Nested Learning sees an ML model as many small learning problems. These problems work together and are trained at the same time. We say the model's structure and training rules are the same idea. They are just different levels of learning. Each level has its own information flow and update speed. Nested Learning helps us design better AI. It lets us build learning parts with more depth. This helps stop catastrophic forgetting.
We tested Nested Learning with a special model called \u0022Hope\u0022. It learns language well. It also remembers longer text better than other top models.
The Nested Learning Idea
Nested Learning shows that a complex ML model is really a group of learning problems. These problems fit inside each other or work side-by-side. Each problem uses its own information to learn. This is its context flow.
This means current deep learning methods just shorten their information flow. More importantly, Nested Learning shows a new way to design models. We can build learning parts with more depth.
Think about how we remember things. We link one thing to another. For example, seeing a face might help us remember a name. This is associative memory.
- We show that training, like backpropagation, can work like associative memory. The model learns to link data to its error. This error shows how surprising the data was.
- Other studies also show this. For example, parts of models like the attention in transformers can be seen as simple associative memory. They learn how words in a sentence relate to each other.
The brain's steady structure and different learning speeds are key to how humans learn over time. Nested Learning lets each part of the brain learn at different speeds. It shows that models like transformers and memory modules are just layers that update at different speeds.
We can set an update speed for each part. This means how often a part's settings are changed. This helps us order the learning problems into levels. This order is the main idea of Nested Learning.
Using Nested Learning
The Nested Learning idea gives us clear ways to make current methods and models better:
Smart Trainers
Nested Learning sees trainers, like momentum trainers, as memory modules. This lets us use ideas from memory studies for trainers. Many trainers use simple dot-product. This measures how similar two things are. But it doesn't show how different data points relate. By changing the trainer's goal to a standard loss metric, like L2 regression loss, we can create new versions of concepts like momentum. These new versions handle messy data better.
Memory Systems That Work Together
In a standard Transformer, the model remembers recent text. This is short-term memory. The feedforward neural networks remember old knowledge. This is long-term memory. Nested Learning makes this idea bigger. It creates a "continuum memory system" (CMS). Memory is now a range of modules. Each module updates at its own speed. This makes a better memory system for learning over time.
Hope: A Model That Changes Itself
We built a test model called Hope. It uses Nested Learning. Hope is based on the Titans model. Titans models are good at remembering things. They rank memories by how surprising they are. But they only update their settings twice. Hope is a self-changing model. It can learn in many ways. It also uses CMS blocks. This helps it handle longer text. It can improve its own memory by looking back at itself. This creates a model that can learn over and over.
Tests
We ran tests to see if our smart trainers work well. We also checked how Hope performed on language tasks, long-text tasks, learning new things, and using knowledge. You can find all the results in our paper.
Results
Our tests show that Nested Learning, continuum memory systems, and self-changing Titans are powerful. Hope learned language and solved common-sense problems better than other modern models.
On many language and common-sense tasks, the Hope model had lower perplexity and higher accuracy. This was better than current recurrent models and standard transformers.
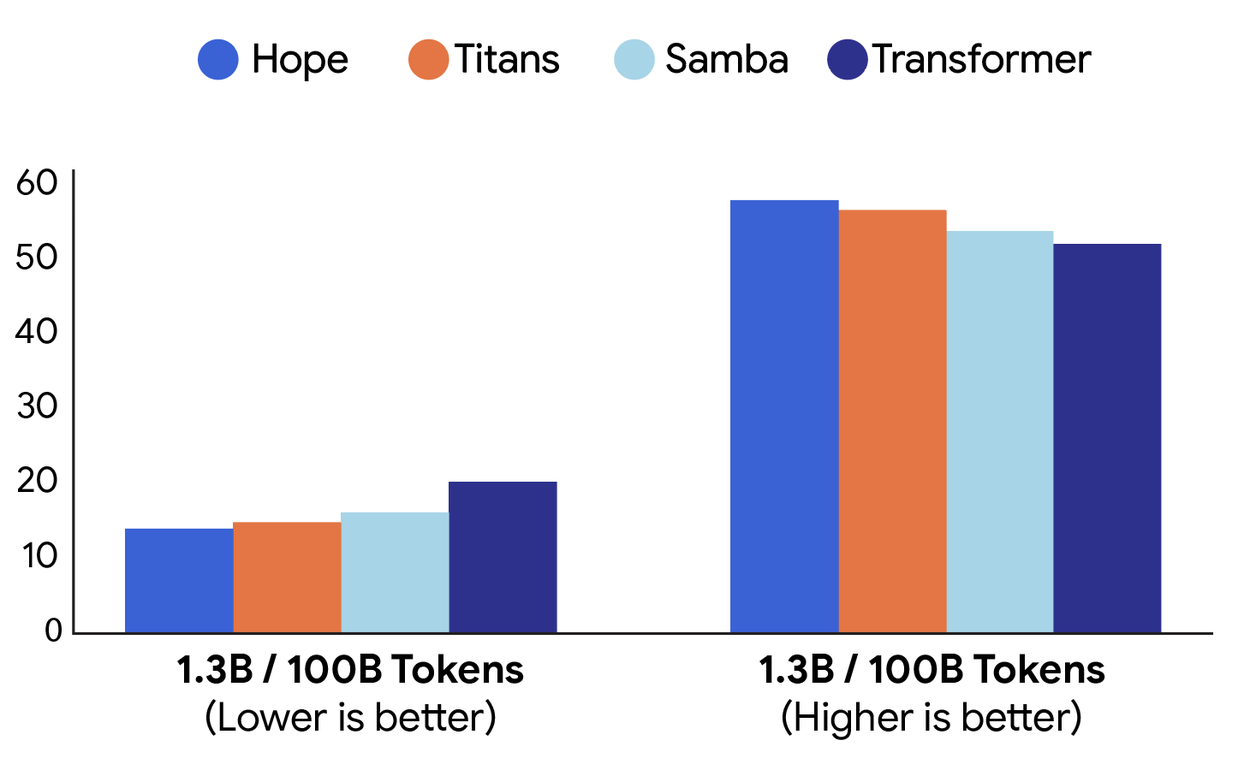
Here is a comparison of how different models performed. We looked at language learning (perplexity; left) and common-sense solving (accuracy; right). Hope did better than Titans, Samba, and a basic Transformer.
Hope also showed better memory skills on long-text tasks. This proves that CMSs are a good way to handle long pieces of information.
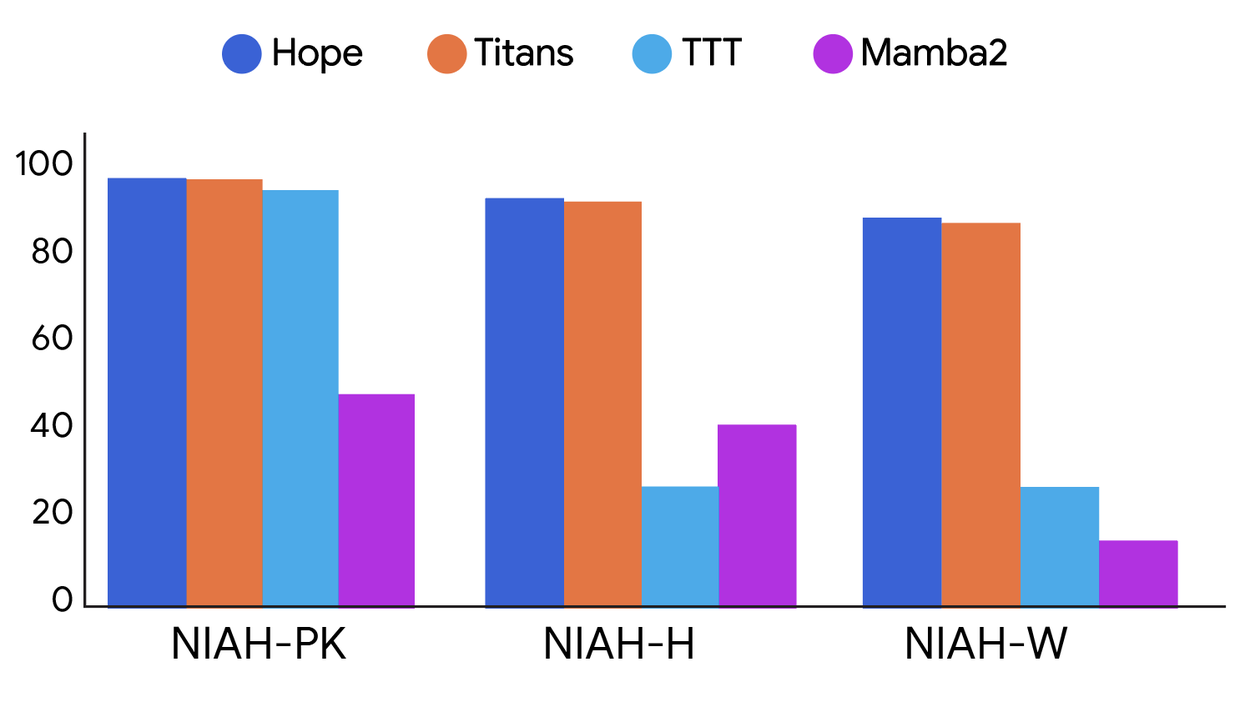
Here, we compare how models did on long-text tasks. Hope and Titans did better than TTT and Mamba2. We tested tasks with easy, medium, and hard difficulty.
Conclusion
Nested Learning is a new way to think about deep learning. It treats model structure and training as one system. This system has many learning problems nested together. This opens up new design options with many layers. Models like Hope show that combining these parts well can create better and more efficient learning methods.
We think Nested Learning can help close the gap. Current models forget things easily. The human brain learns continuously. We are excited for others to explore this new area. Together, we can build smarter AI that keeps learning.